
728x90

* 출력이 다크모드로 되어있어서 라이트모드로 보시면 편리해요!!
☑️ 열화상 카메라 객체인식 및 이상판별 데이터 활용 경진대회
- 주관 : 대전도시철도공사 컨소시엄 X (주)WNCW)
- 주제 : 열화상 이미지에서 객체를 인식하고, 해당 객체의 이상여부를 판별하는 모형 개발
- 기간 : 12/1 (접수) ~ 12/3 (테스트셋 배포) ~ 12/8 (제출)
- 웹사이트 : https://www.2021aidatahackathon.com/
- 팀원 : 류태규, 권재우 (2명)
- 최종성적 : 2등 최우수상 (map 0.87)
-

☑️ 프로젝트 설명
주어진 열화상 데이터를 학습해 카테고리별로 분류해주는 모델을 만드는 대회
모델 성능을 테스트하는 방법으로 mAP가 평가기준
☑️ 진행 사항
1. Data 살펴보기
- 라벨
- 아래와 같이 11개 종류의 기기와 각각의 이상여부까지 총 22개 클래스의 라벨이 존재.
- 전혀 데이터가 없는 클래스도 있음.
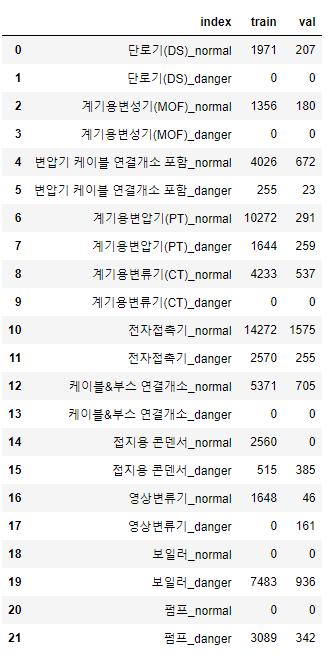
- 라벨 형식은 한 이미지 당 하나의 coco 형식 json 파일로 존재
- 이미지
- 약 28,000개의 열화상 이미지 (영상을 프레임별로 잘라놓은 이미지)

- 약 28,000개의 열화상 이미지 (영상을 프레임별로 잘라놓은 이미지)
2. 모델 선정 및 전처리
- 모델 : YOLOv5s
- 선정 이유 :
- 객체 인식분야에서 가장 유명한 모델로, 특히 v5s는 학습이 빠르며, pytorch를 사용하여 다루기가 상대적으로 친숙했기 때문.
- FastRCNN이나 기타 Transformer 모델들은 사용해보고 싶었으나 시간이 부족하여 처음부터 공부하고 실험해보고 할 수가 없었다.
- 전처리
- 경진대회의 특성상 이미지나 라벨 데이터 자체는 모두 깔끔하게 정리가 되어있었기 때문에 따로 전처리가 필요하진 않았다.
- YOLOv5를 사용하기 위하여 라벨의 형식만 coco에서 yolo로 바꾸어주었다.
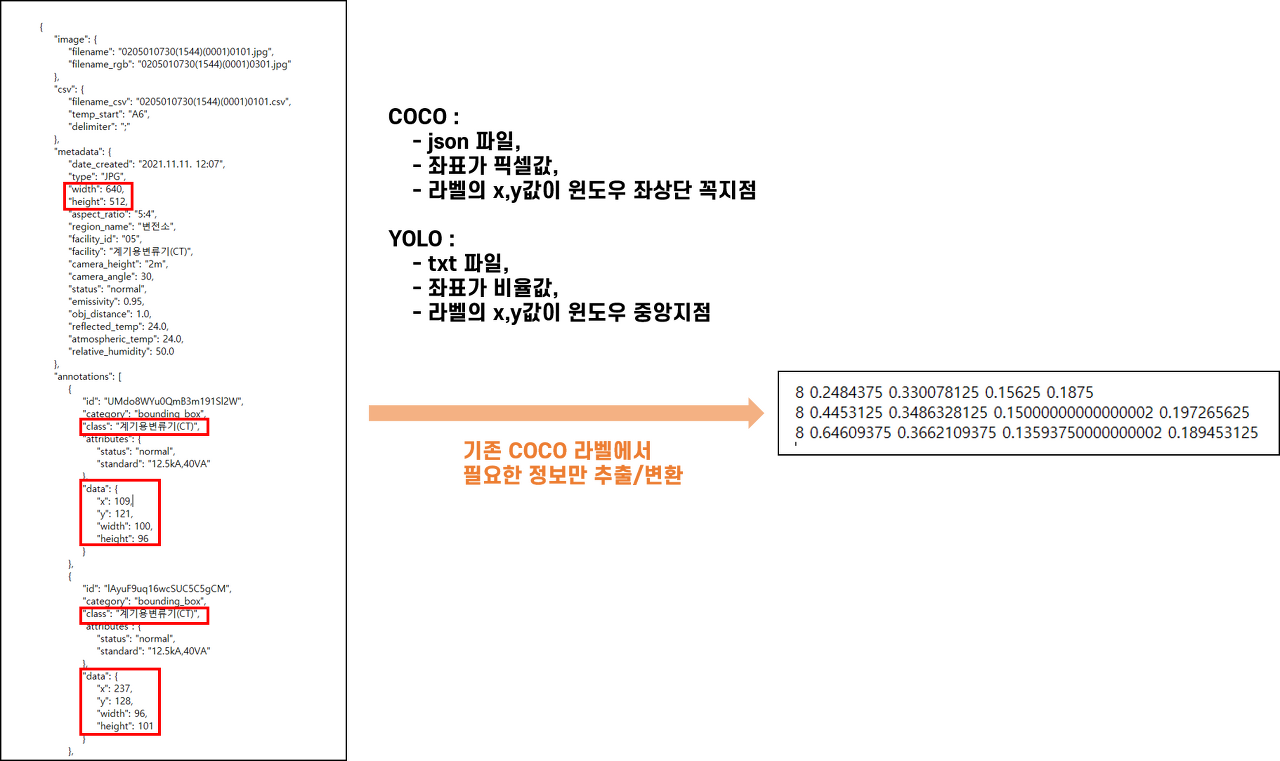
- 우선 베이스라인 모델을 먼저 만들어보기 위해 image augmentation 등은 아직 하지 않았다.
3. 베이스라인 모델
- 데이터가 처음부터 train/val set이 나눠져 있었기 때문에 그대로 적용하여 베이스모델 학습
- Parameters : batch size 64, epoch 5
- 성능
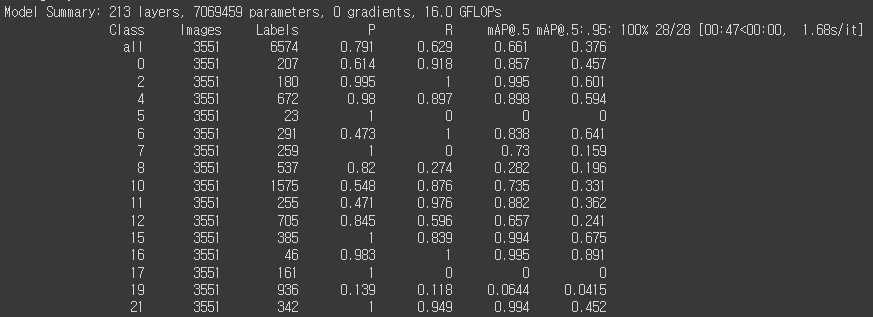
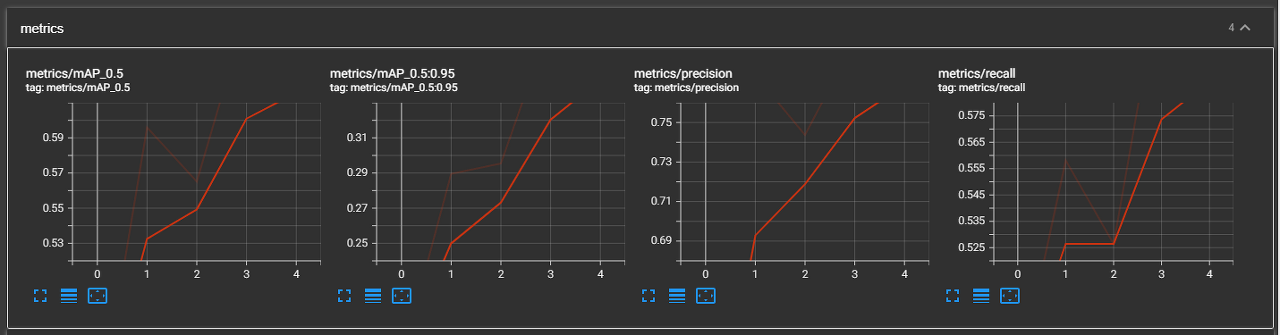
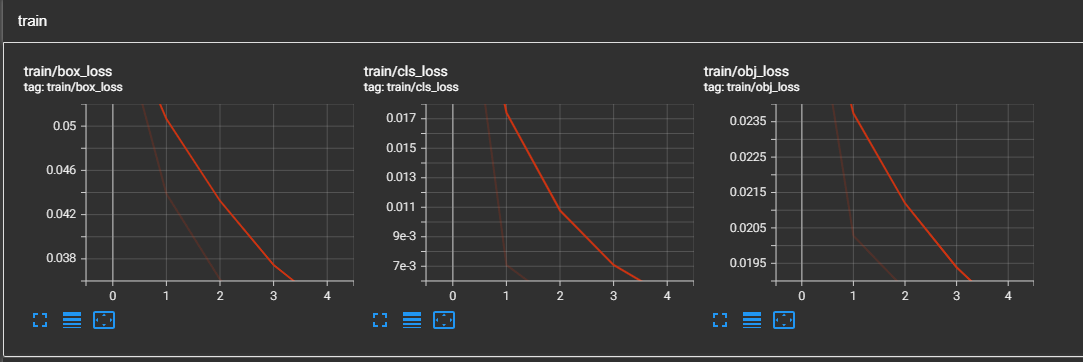
- 모델 평가 / 분석
- map 곡선을 봤을땐, 상승 추세에 있으므로 epoch를 늘리면 성능이 오를 여지가 있다.
- → epoch를 조금씩 늘려 최적의 epoch 찾아보기
- Recall 값이 0 혹은 매우 낮은 클래스들이 있다. 모델이 해당 클래스들을 거의 탐지하지 못한다.
- → 우선 모델이 예측한 결과와 실제 validation set 비교확인 해보기
- map 곡선을 봤을땐, 상승 추세에 있으므로 epoch를 늘리면 성능이 오를 여지가 있다.
4. 개선 모델 1
- 우선 epoch를 늘려서 다시 학습 진행
- 이전과 조건이 같으므로, 학습했던 모델의 best weight를 가져와 추가 학습 epoch 3회 → 다시 epoch 10회 추가 학습 (시간이 많지 않고, 학습에 시간이 4~5시간씩 걸려서 epoch를 많이 늘리지 못했다.)
- 성능

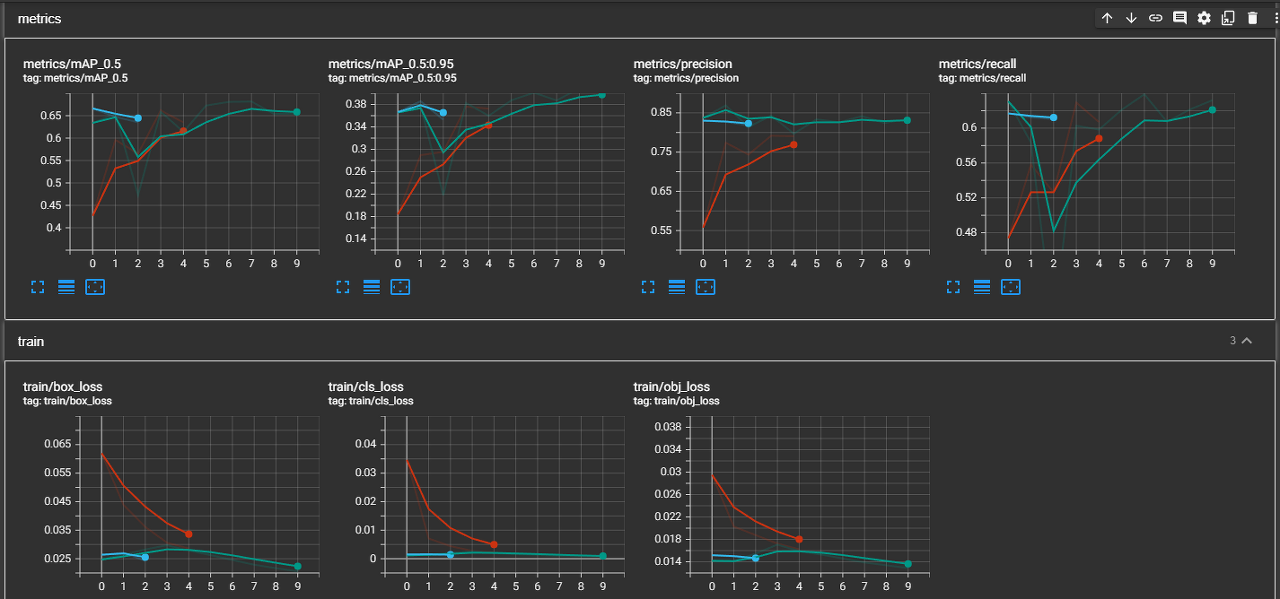
- 모델 평가 / 분석
- map 곡선이 이미 평평해졌고, loss도 없는 수준이라 더이상 epoch 조절로는 성능을 올릴 수 없다 판단됨.
- → 혹시 모르니 batch size 줄여보기
- recall 값을 보아도 이전에 탐지하지 못했던 클래스들을 여전히 탐지하지 못함. 개선이 전혀 없음.
- → 데이터 살펴보면서 왜 탐지하지 못하는지 분석해보기
- map 곡선이 이미 평평해졌고, loss도 없는 수준이라 더이상 epoch 조절로는 성능을 올릴 수 없다 판단됨.
5. 데이터 살펴보기 2
- 가장 먼저 탐지되지 못했던 클래스들의 train / val set를 살펴보았다. 그 결과, train set의 기기 모양과 validation set의 기기 모양이 확연히 다름을 발견했다. 거의 불독 사진만 주고 치와와의 사진이 강아지인지 맞추라는 것 같았다.


- 결국 해당 클래스의 탐지 성능을 올리기 위해선 validation set에만 있는 모양들을 train set과 합쳐야 했다. 이러면 ‘정보의 누수’ 문제가 발생할 것이 분명했지만, 직접 새로운 데이터를 구할 수는 없으므로 어쩔 수 없는 것 같았다. 또한, 불행인지 다행인지 test set을 받고 확인해보니 대부분이 validation set에서 가져온 이미지들이었다.
5. 개선모델_2 (최종 모델)
- Train set과 Validation set을 섞은 후, 최종 모델을 만들었다.
- Parameters : batch 32, epochs 10, weights 이전 모델 가중치 적용
- 성능 : train/val set을 섞었기 때문에 validation 성능은 사실 볼 필요가 없었다.
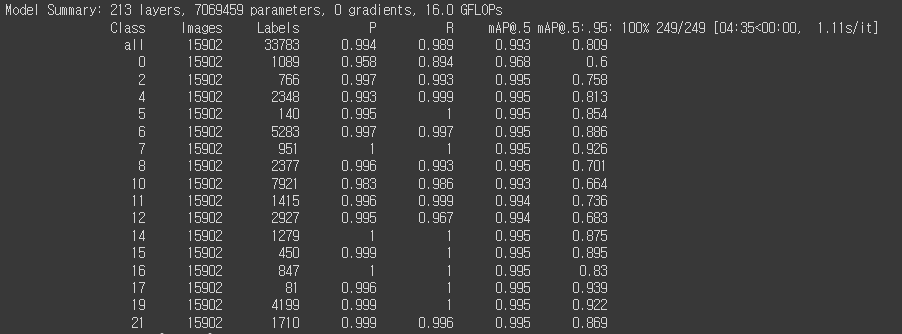
6. Test set 예측 및 결과 확인
- 최종 모델로 test set (약 3,700여 장)에 대한 추론 진행
- 문제
- confidence level에 따른 인식률 문제 (약 600여 장)
- confidence level(0.3 ~ 0.5)을 높일 경우, 일부 객체를 제대로 탐지하지 못함
- confidence level(0.1 ~ 0.2)을 낮출 경우, 모든 클래스가 너무 과하게 탐지됨.
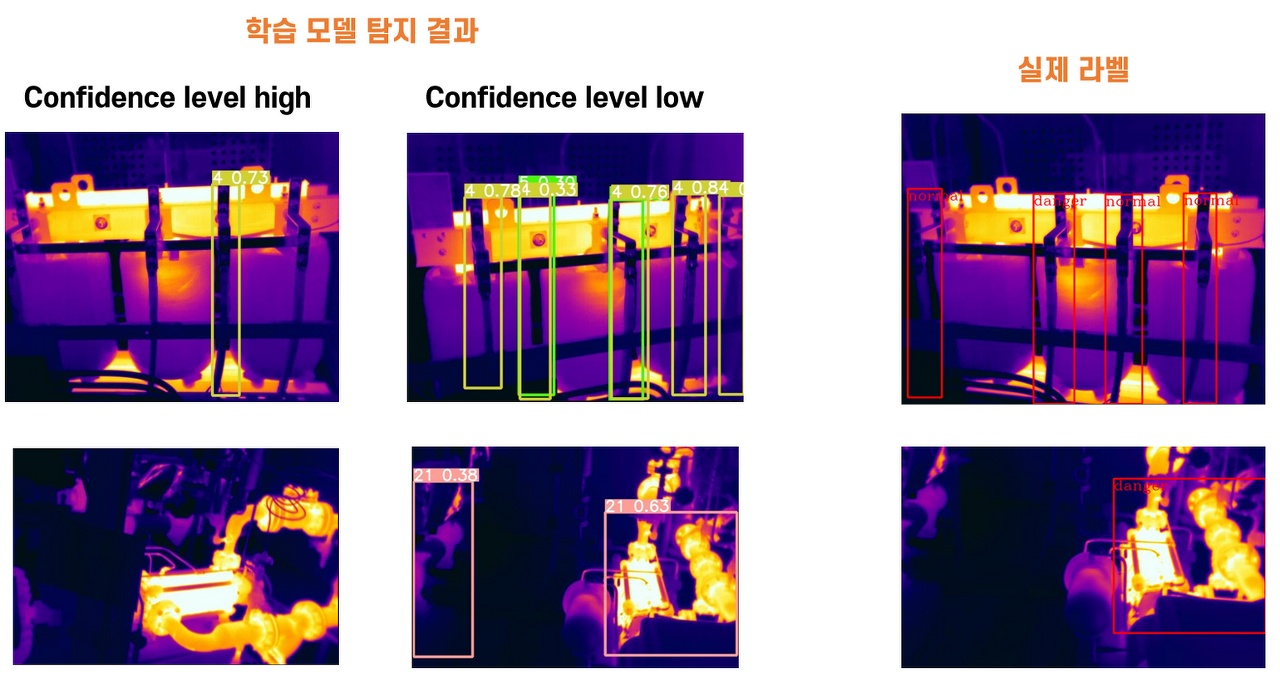
- confidence level과 무관하게 아예 탐지를 못하는 이미지 (약 300여 장)
- 보일러, 펌프의 경우 비슷한 이미지를 학습했음에도 인식하지 못하는 것들이 있음.

- 보일러, 펌프의 경우 비슷한 이미지를 학습했음에도 인식하지 못하는 것들이 있음.
- confidence level에 따른 인식률 문제 (약 600여 장)
7. Test set 문제 개선
- Confidence level 문제 : 적당한 값을 찾은 뒤, 수작업으로 라벨값을 수정
- 다른 클래스들에 영향을 주지 않는 선에서 조금은 과하게 탐지하도록 conf 값을 맞추었고, 이후 실제 이미지와 비교하면서 라벨이 없어야 하는 곳에 있는 경우만 삭제했다. 사실 confidence level을 보수적으로 설정하면 recall 값만 약간 낮아지지만, 관대하게 설정하면 precision값이 과하게 떨어질 수 있기 때문에 안전한 점수를 위해서는 confidence level만 낮추고 끝내는 것이 좋을 수도 있었다. 하지만, confidence level을 조절하면서 육안으로 보았을 때, 이정도는 직접 수작업으로도 할만하겠다 싶은 값을 찾을 수 있었고, 결과적으론 좋은 선택이었던 것 같다.
- 추론을 못하는 이미지 문제 : 해당 클래스만 구별하는 모델 추가
- 때문에 rotation값을 조정한 image augmentation을 살짝 추가해서 해당 클래스만 학습한 모델을 따로 만들었다. 여기서 rotation은 yolo 모델 내의 parameter를 통해서만 진행했다.그 결과, 약 300여 장 중 180여장은 제대로 추론할 수 있었고, 나머지 120여장은 시간상 포기해야 했다.추론을 하지 못한 300여 장을 모아보니 모두 보일러, 펌프에 해당하는 이미지임을 알 수 있었다. 또한, 주로 각도가 틀어진 사진을 추론하지 못하는 듯 했다.

- 때문에 rotation값을 조정한 image augmentation을 살짝 추가해서 해당 클래스만 학습한 모델을 따로 만들었다. 여기서 rotation은 yolo 모델 내의 parameter를 통해서만 진행했다.그 결과, 약 300여 장 중 180여장은 제대로 추론할 수 있었고, 나머지 120여장은 시간상 포기해야 했다.추론을 하지 못한 300여 장을 모아보니 모두 보일러, 펌프에 해당하는 이미지임을 알 수 있었다. 또한, 주로 각도가 틀어진 사진을 추론하지 못하는 듯 했다.
☑️ 최종 결과 및 회고
- 최우수상, map 0.87
캐글이나 데이콘 같이 큰 대회가 아니라서 공개적으로 제출 결과를 볼 수 있는 채널은 없었지만, 2등 최우수상을 수상하게 되었다. 시상식에서 살짝 물어보니 map는 0.87임을 알려주었고, 사실 1,2등을 제외한 나머지는 모두 map가 0.2 ~ 0.3대 였다고 한다.
- 어떻게 수상했나
아무래도 시간이 1주일밖에 없었고, 위에 서술했던 train / val set의 문제도 있다보니 다른 참가자들의 점수가 제대로 나오지 못했던 것 같다. 짧은 시간 속에서도 빠르게 문제를 파악하고 최선의 방안을 선택했던 것이 도움이 되었던 듯 하다.
코랩 무료버전으로 모델을 학습함에 있어서 너무 오래 걸려서(약 1에포크당 1시간30분) 코랩 프로를 결제 할 수 밖에 없었고 결제를 했지만 성능적으로 많은 차이가 없었다. 그래서 학습을 많이 못한 모델로 결과를 제출했고 GPU의 성능이 좋았으면 더 좋은 결과가 있었을텐데의 아쉬움이 있다.
728x90
'IT이야기' 카테고리의 다른 글
| 딥러닝 _ 성능 100%의 정확도 이미지 분류모델 만들기 (222) | 2021.09.04 |
|---|---|
| (데이콘) ML _ Project : 구내식당 요일별 점심, 저녁 식수 인원 예측 (0) | 2021.07.25 |
| Project : 다음 분기에 어떤 게임을 설계해야 할까? (0) | 2021.06.13 |
| [라이트봇] light bot 3단계 3-1 ~ 3-6 정답 (0) | 2021.05.22 |
| [라이트봇] light bot 2단계 2-1 ~ 2-6 정답 (0) | 2021.05.22 |