
Machine Learning _ Project(데이콘 _ 한국주택토지공사 주관)
▷ 주제 : 구내식당 요일별 점심, 저녁 식사 식수 인원 예측

▷ 프로젝트 설명 / 목적
과거 아르바이트를 하면서 다음날 매장에 고객이 얼마나 오는지 예측할 수 있으면 재료를 효율적으로 관리 할 수 있지 않을까? 그리고 매출을 예측할 수 있지 않을까? 라는 궁금중이 생겼고 데이콘에서 비슷한 데이터가 있어서 주제를 선정하게 되었습니다.
회사에서는 직원들의 식당 수요를 파악해서 재료가 남아서 버리는 불필요한 비용을 줄이고 싶어합니다.
이번 저의 프로젝트에서는 대기업의 인적 자원 데이터를 바탕으로
직원들이 요일별로 점심, 저녁식사를 얼마나 하는지, 식수 인원 예측모델을 만들어 봤습니다.
Data Description
- Dataset : DACON(구내식당 식수 인원 예측 AI 경진대회)
- Target 1 : 중식계
- Target 2 : 석식계
- Data
- 일자
- 요일 : 월, 화, 수, 목, 금
- 본사정원수 : 본사 총 인원 (시기별로 본사인원이 차이남)
- 본사휴가자수
- 본사출장자수 (휴가자와 출장자는 식수인원에서 제외)
- 현본사소속재택근무자수 (식수인원에서 제외)
- 시간외근무명령서승인건수 (야근을 많이 하는지 확인)
- 조식메뉴
- 중식메뉴
- 석식메뉴
- 데이터 가설 설정
- 코로나 전후로 식사에 영향이 있을까?
- 코로나 전후로 재택근무가 생겨난 것일까?
- 요일에 따른 중식, 석식 식사량에 차이가 있을까?
- 데이터 불러오기
# 데이터 불러오기
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
url_train = "https://raw.githubusercontent.com/ZeusKwon/data-drive/main/235743_%EA%B5%AC%EB%82%B4%EC%8B%9D%EB%8B%B9%20%EC%8B%9D%EC%82%AC%20%EC%9D%B8%EC%9B%90%20%EC%98%88%EC%B8%A1%20AI%20%EA%B2%BD%EC%A7%84%EB%8C%80%ED%9A%8C_data/train.csv"
url_test = "https://raw.githubusercontent.com/ZeusKwon/data-drive/main/235743_%EA%B5%AC%EB%82%B4%EC%8B%9D%EB%8B%B9%20%EC%8B%9D%EC%82%AC%20%EC%9D%B8%EC%9B%90%20%EC%98%88%EC%B8%A1%20AI%20%EA%B2%BD%EC%A7%84%EB%8C%80%ED%9A%8C_data/test.csv"
url_submission = "https://raw.githubusercontent.com/ZeusKwon/data-drive/main/235743_%EA%B5%AC%EB%82%B4%EC%8B%9D%EB%8B%B9%20%EC%8B%9D%EC%82%AC%20%EC%9D%B8%EC%9B%90%20%EC%98%88%EC%B8%A1%20AI%20%EA%B2%BD%EC%A7%84%EB%8C%80%ED%9A%8C_data/sample_submission.csv"
train = pd.read_csv(url_train)
test = pd.read_csv(url_test)
submission = pd.read_csv(url_submission)- 데이터 결측치 확인
# train 데이터 결측값 확인
train.isna().any()
# test 데이터 결측값 확인
test.isna().any()
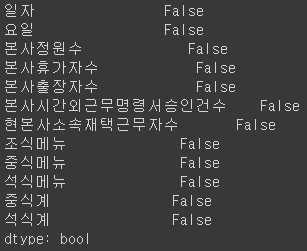

- train, test 데이터 둘다 결측값이 없음
베이스라인 설계
- 데이터 정리 (타겟 분리)
train['요일'] = train['요일'].map({'월':0, '화':1, '수':2, '목':3, '금':4})
test['요일'] = test['요일'].map({'월':0, '화':1, '수':2, '목':3, '금':4})
x_train = train[['요일', '본사정원수', '본사출장자수', '본사시간외근무명령서승인건수', '현본사소속재택근무자수']]
y1_train = train['중식계']
y2_train = train['석식계']
x_test = test[['요일', '본사정원수', '본사출장자수', '본사시간외근무명령서승인건수', '현본사소속재택근무자수']]- 점심과 저녁을 예측할 모델 2개 생성 및 학습
# 최다 클래스의 빈도가 정확도가 됩니다.
from sklearn.metrics import accuracy_score
params = {
'min_samples_leaf' :[10,12,15],
'max_depth' : [1, 5, 10, 20],
}
model1 = RandomForestRegressor(n_jobs=-1, random_state=42)
model2 = RandomForestRegressor(n_jobs=-1, random_state=42)
lunch_model = RandomizedSearchCV(model1, params, scoring='neg_mean_absolute_error')
dinner_model = RandomizedSearchCV(model2, params, scoring='neg_mean_absolute_error')
lunch_model.fit(x_train, y1_train)
dinner_model.fit(x_train, y2_train)
lunch_best = lunch_model.best_score_
dinner_best = dinner_model.best_score_
print('점심 베이스라인 모델 에러값(mae) : ',lunch_best)
print('저녁 베이스라인 모델 에러값(mae) : ', dinner_best)- 베이스라인 스코어 ( MAE )
- 점심 베이스라인 모델 성능 : -91.67910737123546
- 저녁 베이스라인 모델 성능 : -85.18297694820244
목표 : 이 모델의 에러값보다 낮은 모델을 만들어보겟습니다.
EDA _ 데이터 전처리
- 칼럼명 수정하기
# 일자 : date, 요일 : dow, 본사정원수 : employees, 본사휴가자수 : dayoff
# 본사출장자수 : bustrip, 본사시간외근무명령서승인건수 : ovtime, 현본사소속재택근무자수 : remote
train_eng = train.copy()
test_eng = test.copy()
train_eng.columns = ['date', 'dow', 'employees', 'dayoff', 'bustrip', 'ovtime', 'remote', 'brk', 'ln', 'dn', 'target_ln', 'target_dn']
test_eng.columns = ['date', 'dow', 'employees', 'dayoff', 'bustrip', 'ovtime', 'remote', 'brk', 'ln', 'dn']- 타겟 분포 확인
fig, ax = plt.subplots(nrows = 1, ncols = 2, figsize = (18, 4))
sns.distplot(train_eng["target_ln"], ax = ax[0], color = 'orange', kde = False, rug = True)
sns.distplot(train_eng["target_dn"], ax = ax[1], kde = False, rug = True)
plt.show()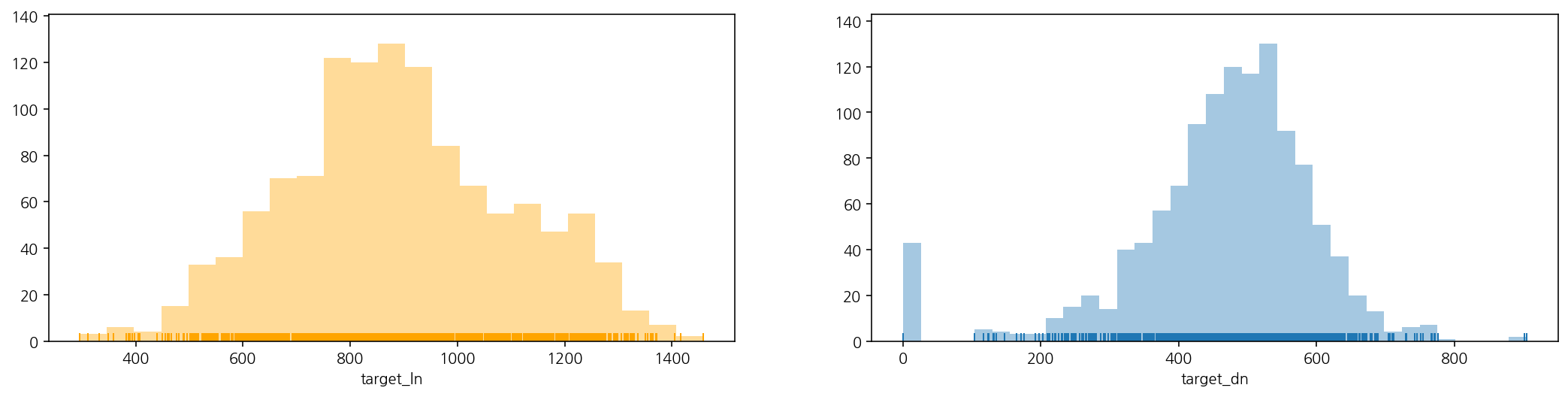
- 저녁 이용자수는 특이하게 0명인 날이 존재하는 것 같음(저녁의 mae값을 줄이는데 주력해야할듯) 그리고 이용자수는 몇 백명 (100~800여 명) 정도의 범위이고, 전반적으로 점심보다 저녁 이용자수가 더 적다.
- 코로나 전후 점심과 저녁 이용자수 평균 변화 확인
before_covid = train_eng[(train_eng['date'] >= '2019-01-01')&(train_eng['date'] <= '2019-12-31')][['date', 'target_ln', 'target_dn']]
after_covid = train_eng[train_eng['date'] >= '2020-01-01'][['date', 'target_ln', 'target_dn']]
print('점심:', '2019년에는', round(before_covid.target_ln.mean(), 2), ', 2020년에는', round(after_covid.target_ln.mean(), 2))
print('저녁:', '2019년에는', round(before_covid.target_dn.mean(), 2), ', 2020년에는', round(after_covid.target_dn.mean(), 2))점심: 2019년에는 850.51 , 2020년에는 890.97
저녁: 2019년에는 445.39 , 2020년에는 428.34
2019년과 2020년만을 따로 보니, 딱히 코로나19로 인해 점심/저녁 이용자수가 크게 달라진 것 같진 않음
- 오히려 점심의 경우, 2020년 이용자수 평균(890명)이 2019년(850명)보다 높았다.
혹시 2020년동안 총 직원수가 늘어나서 그런건지 확인
train_eng1 = train_eng
def year1(str):
return str[0:4]
train_eng1['year'] = train_eng['date'].apply(year1)
train_eng1 = train_eng1[['employees','year']].groupby(train_eng1['year']).sum()
train_eng1
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [15, 6]
colors = ['silver', 'silver','silver', '#d395d0', 'firebrick', 'silver']
wedgeprops={'width': 0.7, 'edgecolor': 'w', 'linewidth': 5}
plt.pie(train_eng1['employees'],labels = train_eng1.index, startangle=260, autopct='%.2f%%',
shadow=True, colors = colors, explode = [0,0,0,0.1,0.1,0],wedgeprops=wedgeprops);
- 2019년과 2020년만을 비교해보면 딱히 2020년 정원수가 더 많다고는 할 수 없을 것 같다.
2019년에 비해 2020년의 총인원수가 늘지 않았기 때문에 코로나의 영향이 있다고 보입니다. 코로나로 인해서 점심외출을 줄이고 사내에서 식사를 했다라고 볼 수 있을 것 같습니다.
이전에 석식 이용자수를 확인했을 때 0명인 날들이 있었는데 이게 오류인건지, 아니면 어떤 이유가 있어서인지 확인
train_eng[train_eng.target_dn == 0][['date', 'dayoff', 'bustrip', 'ovtime', 'remote', 'dow', 'dn', 'target_dn']].head()
len(train_eng[train_eng.target_dn == 0][['date', 'dayoff', 'bustrip', 'ovtime', 'remote', 'dow', 'dn', 'target_dn']])43
저녁 이용자가 0명이었던 이유(총 43개)
- 월별 마지막 (또는 그 전 주) 수요일(dow가 3인 날)은 '자기개발의 날'이라서 모두 정시 퇴근을 하는 (해야하는)날, 그래서 매달 마지막 수요일마다 0명이 있음
- 저녁 메뉴가 제공됨에도 불구하고 저녁 이용자가 0명인 날이 딱 2일 있습니다. 2017-09-27와 2018-02-14 입니다. 이 날들은 긴 공휴일 전후의 날짜일까 싶어 확인
- 예전 달력을 확인해보니, 2017-09-27은 공휴일 직전은 아니었지만, 2017년의 유명한 황금연휴 전 주 개천절, 추석, 대체휴일, 한글날까지 황금연휴
- 2018-02-14은 예상대로 2018-02-15 ~ 17일까지의 설날 연휴 전날
예측모델에서 마지막주 수요일의 인원을 0명으로 설정
- 시각화 및 상관관계 분석
- 타겟칼럼 상관관계 히트맵
train.corr()[['중식계', '석식계']]
sns.heatmap(train.corr()[['중식계', '석식계']]);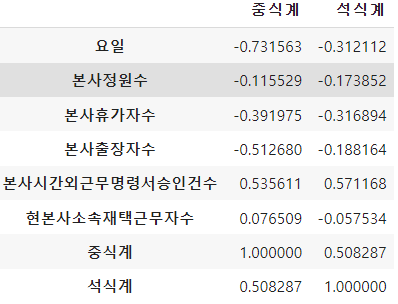

- 중식
- 요일
- 본사시간외근무명령서승인건수
- 본사출장자수
- 석식
- 본사시간외근무명령서승인건수
- 요일
- 휴가자
타겟으로 상관관계를 나타내면 중식과 석식에서 비슷한 칼럼이 높은 상관관계를 보임
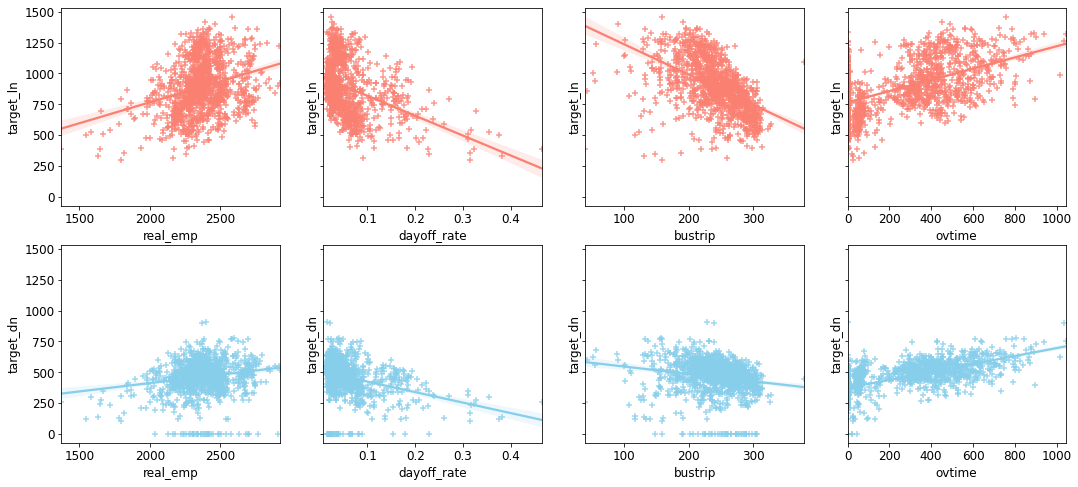
- 산점도 그래프도 상관관계 표와 같은 결과를 보인다.
요일별로 유의미한 차이가 있는지 확인
# 요일단위로 보기
fig, ax = plt.subplots(7)
fig.set_size_inches(10,12)
sns.lineplot(data=train, x='요일', y='식사가능자수', ax=ax[0])
sns.lineplot(data=train, x='요일', y='본사출장자수', ax=ax[1])
sns.lineplot(data=train, x='요일', y='본사시간외근무명령서승인건수', ax=ax[2])
sns.lineplot(data=train, x='요일', y='중식계', ax=ax[3])
sns.lineplot(data=train, x='요일', y='석식계', ax=ax[4])
sns.lineplot(data=train, x='요일', y='중식참여율', ax=ax[5])
sns.lineplot(data=train, x='요일', y='석식참여율', ax=ax[6])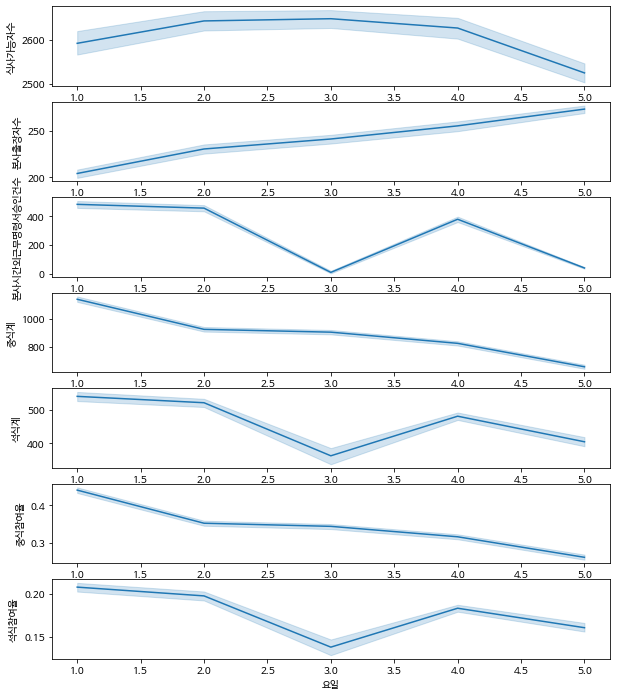
- 중식계는 월화수목금의 순으로 그래프가 나타나는데
- 석식계는 야근인원의 비율과 비슷한 비율로 월화목금수 순으로 그래프가 나타남
- 특성공학
# 일자, 요일은 라벨 인코딩으로 숫자형으로 변환
train_eng['month'] = pd.DatetimeIndex(train_eng['date']).month
test_eng['month'] = pd.DatetimeIndex(test_eng['date']).month
train_eng['day'] = pd.DatetimeIndex(train_eng['date']).day
test_eng['day'] = pd.DatetimeIndex(test_eng['date']).day
# 요일을 숫자로 변환
weekday = {
'월': 1,
'화': 2,
'수': 3,
'목': 4,
'금': 5
}
train_eng['dow'] = train_eng['dow'].map(weekday)
test_eng['dow'] = test_eng['dow'].map(weekday)
# 식사가능자수 = 본사정원수 - 본사휴가자수 - 현본사소속재택근무자수
train_eng['real_emp'] = train_eng['employees'] - train_eng['bustrip'] - train_eng['dayoff'] - train_eng['remote']
test_eng['real_emp'] = test_eng['employees'] - train_eng['bustrip'] - test_eng['dayoff'] - test_eng['remote']
# 정확한 식사 참여율 칼럼 만들기
train_eng['ln_rate'] = train_eng['target_ln'] / train_eng['real_emp']
train_eng['dn_rate'] = train_eng['target_dn'] / train_eng['real_emp']
# 비율로 전환
train_eng['dayoff_rate'] = train_eng['dayoff']/train_eng['employees']
train_eng['bustrip_rate'] = train_eng['bustrip']/train_eng['employees']
train_eng['ovtime_rate'] = train_eng['ovtime']/train_eng['real_emp']
train_eng['remote_rate'] = train_eng['remote']/train_eng['employees']
test_eng['dayoff_rate'] = test_eng['dayoff']/test_eng['employees']
test_eng['bustrip_rate'] = test_eng['bustrip']/test_eng['employees']
test_eng['ovtime_rate'] = test_eng['ovtime']/test_eng['real_emp']
test_eng['remote_rate'] = test_eng['remote']/test_eng['employees']
train_ln = train_ln.drop('ln',axis=1)
features = ['month', 'day', 'dow', 'real_emp', 'bustrip', 'ovtime','remote','dayoff_rate','bustrip_rate','ovtime_rate','remote_rate']
labels = ['target_ln','target_dn', 'ln_rate', 'dn_rate']
train_eng = train_eng[features+labels]
test_eng = test_eng[features]# 요일을 석식 rank에 맞춰 mapping한 요일(석식) 칼럼 만들기.
weekday_rank4dinner = {
1: 1,
2: 2,
3: 5,
4: 3,
5: 4,
}
train_eng['dow_dn'] = train_eng['dow'].map(weekday_rank4dinner)
test_eng['dow_dn'] = test_eng['dow'].map(weekday_rank4dinner)- 메뉴칼럼(중식) 전처리

메뉴칼럼을 어떻게 전처리 해야하는지 고민이 많이 들었음
결론으로는 메뉴별로 나눠서 특정 메뉴만 가지고 모델학습에 사용하기로 결정
# 메뉴에서 불필요한 문자 제거
lunch = []
for day in range(len(train_eng)):
tmp = train_eng.iloc[day, 8].split(' ') # 공백으로 문자열 구분
tmp = ' '.join(tmp).split() # 빈 원소 삭제
search = '(' # 원산지 정보는 삭제
for menu in tmp:
if search in menu:
tmp.remove(menu)
lunch.append(tmp)np.array(train_eng[ (train_eng.index > 1064) & (train_eng.index < 1069)][['date', 'ln']])
메뉴 전처리 과정에서 이상점을 발견
- 메뉴에서 사이드와 김치의 자리가 2020-07-01부터 순서가 바뀐다.
- 2020-0613 ~ 2020-06-30까지는 구내식당이 운영을 하지 않았음
이상점 부분을 반영해서 메뉴칼럼 전처리
# lunch train data에 밥, 국, 반찬 1-3, 김치, 사이드로 구분해서 생성
bob = []; gook = []; banchan1 = []; banchan2 = []; banchan3 = []; kimchi = []; side = []
for i, day_menu in enumerate(lunch):
bob_tmp = day_menu[0]; bob.append(bob_tmp)
gook_tmp = day_menu[1]; gook.append(gook_tmp)
banchan1_tmp = day_menu[2]; banchan1.append(banchan1_tmp)
banchan2_tmp = day_menu[3]; banchan2.append(banchan2_tmp)
banchan3_tmp = day_menu[4]; banchan3.append(banchan3_tmp)
if i < 1067:
kimchi_tmp = day_menu[-1]; kimchi.append(kimchi_tmp)
side_tmp = day_menu[-2]; side.append(side_tmp)
else:
kimchi_tmp = day_menu[-2]; kimchi.append(kimchi_tmp)
side_tmp = day_menu[-1]; side.append(side_tmp)
train_ln = train_eng[['date', 'dow', 'employees', 'dayoff', 'bustrip', 'ovtime', 'remote', 'ln', 'target_ln']]
train_ln['bob'] = bob
train_ln['gook'] = gook
train_ln['banchan1'] = banchan1; train_ln['banchan2'] = banchan2; train_ln['banchan3'] = banchan3
train_ln['kimchi'] = kimchi
train_ln['side'] = side
train_ln.iloc[1066:1070, 7:]
# 밥 데이터 개수 확인
bob_df = pd.DataFrame(train_ln['bob'].value_counts().reset_index())
bob_df.head(10)
# 반찬 데이터 개수 확인
banchan_list = []
for i in range(3):
tmp = train_ln[f'banchan{i+1}']
for j in range(len(train_ln)):
tmp2 = tmp[j]
banchan_list.append(tmp2)
banchan_df = pd.DataFrame(pd.DataFrame(banchan_list).value_counts())
banchan_df.columns = ['banchan']
banchan_df.reset_index(inplace = True)
banchan_df.columns = ['index', 'banchan']
banchan_df.head(10)
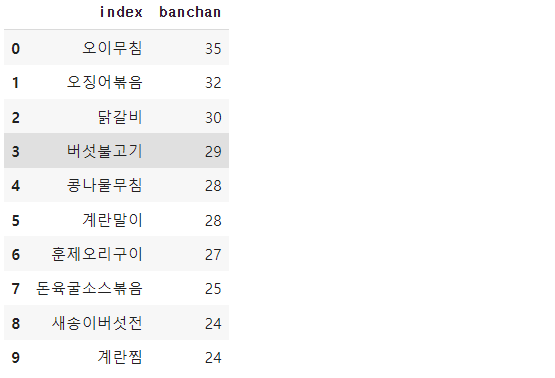
메뉴 데이터와 전처리한 데이터를 합치는데 메뉴의 범주가 너무 많기 때문에 타겟에 영향이 있을것 같은 밥과 메인반찬만 기존데이터에 추가해주었다.
#데이터 합치기
train_cat = pd.concat([train_eng, train_ln[['bob','banchan1']]], axis = 1)
train_cat.head(3)
- 타겟데이터 분리 후 인코딩
## import OneHotEncoder, train_test_split
from category_encoders import OneHotEncoder
from sklearn.model_selection import train_test_split
# 데이터 정리
features = train_cat.columns
labels = ['target_ln','target_dn', 'ln_rate', 'dn_rate']
x1 = train_cat.copy()
x2 = train_cat.copy()
x1 = x1.drop(['target_ln','target_dn', 'ln_rate', 'dn_rate','dow_dn'], axis=1)
x2 = x2.drop(['target_ln','target_dn', 'ln_rate', 'dn_rate','dow'], axis=1)
y_lunch = train_eng['target_ln']
y_dinner = train_eng['target_dn']
train_one = train_cat.drop(['target_ln','target_dn', 'ln_rate', 'dn_rate'], axis=1)
test_one = train_cat.drop(['target_ln','target_dn', 'ln_rate', 'dn_rate'], axis=1)
## 원핫 인코딩
encoder = OneHotEncoder(use_cat_names = True,cols = ['bob','banchan1'])
x1 = encoder.fit_transform(x1)
x2 = encoder.fit_transform(x2)머신러닝 모델 검증 및 성능 확인
- 평가 1 : RandomForestRegressor
# 평가 1
from sklearn.model_selection import GridSearchCV
params = {
'min_samples_leaf' :[10,12,15],
'n_estimators' : [200,300,450],
'max_depth' : [1, 5, 10, 20],
'max_features' : [ 0.2, 0.5, 0.8, 1]
}
lunch_r = RandomForestRegressor()
dinner_r = RandomForestRegressor()
rd_lunch_model = RandomizedSearchCV(lunch_r, params, scoring='neg_mean_absolute_error')
rd_dinner_model = RandomizedSearchCV(dinner_r, params, scoring='neg_mean_absolute_error')
rd_lunch_model.fit(x1, y_lunch)
rd_dinner_model.fit(x2, y_dinner)
rd_lunch_best = rd_lunch_model.best_score_
rd_lunch_model = rd_lunch_model.best_estimator_
rd_dinner_best = rd_dinner_model.best_score_
rd_dinner_model = rd_dinner_model.best_estimator_- 평가 2 : LGBMRegressor
from sklearn.model_selection import GridSearchCV
from lightgbm import LGBMRegressor
params = {
'n_estimators': [100, 200, 500, 700, 800],
'learning_rate': [0.0, 0.1, 0.09, 0.089, 0.08],
'max_depth' : [1, 3, 5, 7, 10, 15, 20],
'sub_sample' : [ 0.2, 0.5, 0.8, 1]
}
lunch_r = LGBMRegressor()
dinner_r = LGBMRegressor()
lgbm_lunch_model = RandomizedSearchCV(lunch_r, params, scoring='neg_mean_absolute_error')
lgbm_dinner_model = RandomizedSearchCV(dinner_r, params, scoring='neg_mean_absolute_error')
lgbm_lunch_model.fit(x1, y_lunch)
lgbm_dinner_model.fit(x2, y_dinner)
lgbm_lunch_best = lgbm_lunch_model.best_score_
lgbm_lunch_model = lgbm_lunch_model.best_estimator_
lgbm_dinner_best = lgbm_dinner_model.best_score_
lgbm_dinner_model = lgbm_dinner_model.best_estimator_- 평가 3 : CatBoost
from catboost import CatBoostRegressor
params = {
'learning_rate': [0.1, 0.09, 0.089, 0.08],
}
lunch_r = CatBoostRegressor()
dinner_r = CatBoostRegressor()
cat_lunch_model = RandomizedSearchCV(lunch_r, params, scoring='neg_mean_absolute_error')
cat_dinner_model = RandomizedSearchCV(dinner_r, params, scoring='neg_mean_absolute_error')
cat_lunch_model.fit(x1, y_lunch)
cat_dinner_model.fit(x2, y_dinner)
cat_lunch_best = cat_lunch_model.best_score_
cat_lunch_model = cat_lunch_model.best_estimator_
cat_dinner_best = cat_dinner_model.best_score_
cat_dinner_model = cat_dinner_model.best_estimator_- 모델링 성능 결과
result = pd.DataFrame({'BaseLine' : [lunch_best,dinner_best],
'RandomForest' : [rd_lunch_best,rd_dinner_best],
'LGBMRegressor' :[lgbm_lunch_best,lgbm_dinner_best],
'CatBoost' : [cat_lunch_best,cat_dinner_best]})
result.index = ['중식계 best score','석식계 best score']
result
최종 모델 / 스코어
catboost모델이 중식, 석식 모두 높은 성능을 보여준다.
최종 모델 = CatBoost 모델
- 중식계 모델 MAE : -77.526155
- 석식계 모델 MAE : -67.981968
머신러닝 모델 해석
모델의 특성중요도에 대해 어떻게 성능을 내는지 확인해보았습니다.
두 중식, 석식 머신러닝 모델 중 더 분포가 다양하고 예측하기 어려운 중식데이터만 가지고 모델의 특성중요도를 알아보았습니다.
- PDP / SHAP
import eli5
from eli5.sklearn import PermutationImportance
perm = PermutationImportance(cat_lunch_model, random_state = 42).fit(x1,y_lunch)
eli5.show_weights(perm, top = 20, feature_names = x1.columns.tolist())

shap.summary_plot(shap_values, x1, plot_type = 'bar')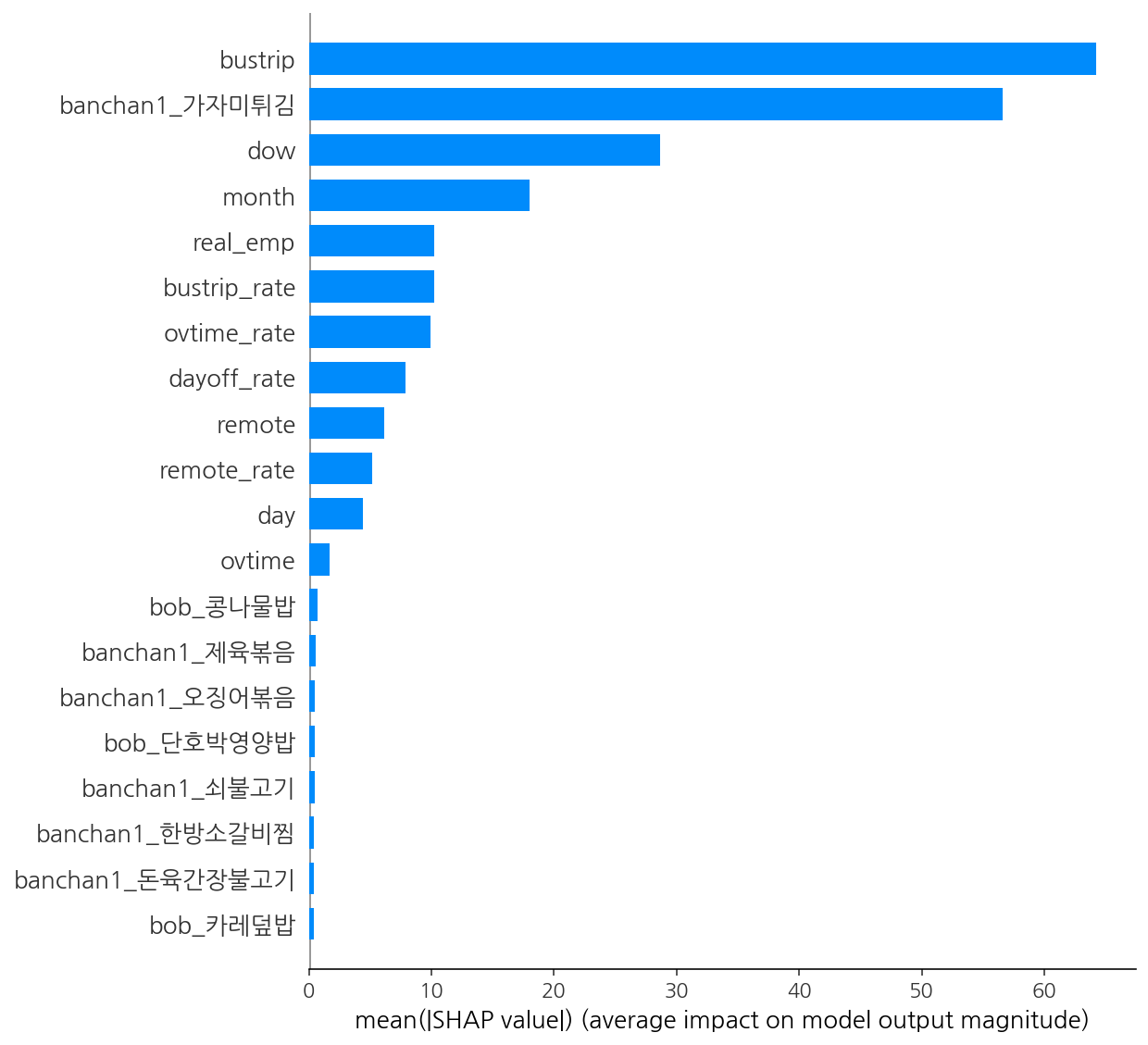
# 모델이 이렇게 예측한 이유를 알기 위하여
# SHAP Force Plot을 그려보겠습니다.
import shap
row = x1.iloc[[1]]
explainer = shap.TreeExplainer(cat_lunch_model)
shap_values = explainer.shap_values(row)
shap.initjs()
shap.force_plot(
base_value=explainer.expected_value,
shap_values=shap_values,
features=row
)
- 특성 중요도가 높으면서 higher 변수는 bustrip이고 다음으로 lower변수인 반찬으로 가자미튀김이 나오면 점심을 잘 안먹는 인사이트를 도출할 수 있었다.
성능 향상 목표
- 날씨 데이터를 접목시켜 비오는날에는 중식을 외부에서 안먹고 사내식당을 이용하는지 확인하면 성능이 높아질 것으로 예상된다.
- 공휴일을 미리 조사해서 공휴일에는 중식, 석식 예측인원을 0으로 적용하면 예측성능이 높아질 것으로 예상된다.
모델의 한계
- 이 모델은 모든 기업에서 그대로 사용할 수 없습니다. 특정 기업의 데이터셋을 바탕으로 만들어진 모델이기 때문에 기업마다 데이터의 수나 분포가 다르게 나타날 것이기 때문에 현재 데이터 상으로는 완벽한 일반화는 불가능합니다.
모델의 향후 목표
- 다른회사의 데이터를 추가해서 모든 회사의 식수인원을 예측할 수 있는 모델을 만드는것이 목표
- 예측모델을 활용하여 예상되는 식수 인원을 미리 파악하면 재료준비와 음식물 쓰래기를 최소화 하는데 도움이 될 수 있다.
대회 결과 및 순위

처음 머신러닝 예측모델 대회를 참여해보았는데 생각보다 좋은 성적을 받아서 어안이 벙벙하긴 했다. 하지만 다음에는 입상을 해보고싶다는 욕심이 생겼고 이번에는 공부를 하면서 경험삼아서 대회에 참가한거라서 추후에 더 집중해서 대회를 해봐야겠다는 생각이 들었다.
'IT이야기' 카테고리의 다른 글
| 딥러닝대회_열화상 이미지 객체탐지 경진대회(입상) (0) | 2021.12.24 |
|---|---|
| 딥러닝 _ 성능 100%의 정확도 이미지 분류모델 만들기 (222) | 2021.09.04 |
| Project : 다음 분기에 어떤 게임을 설계해야 할까? (0) | 2021.06.13 |
| [라이트봇] light bot 3단계 3-1 ~ 3-6 정답 (0) | 2021.05.22 |
| [라이트봇] light bot 2단계 2-1 ~ 2-6 정답 (0) | 2021.05.22 |