![[로그파싱기술] "Drain3" with python](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FnvyCn%2FbtrIXWzz5fQ%2FSGZCC9Hf1sDnTcgL6Xrizk%2Fimg.png)
로그파싱기술 _ Drain3
이 글은 이전에 설명했던 Drain 자동로그 파싱 기법을 기반으로 IBM에서 만든 Drain3을 소개하는 글이다.
Drain기법에 대한 자세한 설명을 확인하려면 아래 링크를 클릭
https://zeuskwon-ds.tistory.com/85?category=0
[논문_로그파싱기술] Drain: An Online Log Parsing Approach with FixedDepth Tree 리뷰 with python
자동 로그파싱기술 _ Drain 알고리즘 오늘은 자동 로그파싱 기술은 Drain 알고리즘에 대해서 논문위주의 설명을 하려고 한다. 목차 Drain Drain 자료 Drain 알고리즘 Drain 성능 1. Drain 논문, 오픈소스 자
zeuskwon-ds.tistory.com
1. Drain 3
Drain을 기반으로 IBM에서 만든 Drain3은 Python 3버전을 효율적으로 지원하기 위해 개발된 오픈소스 라이브러리이다.

1) Drain3 주소
GitHub - IBM/Drain3: Drain log template miner in Python3
Drain log template miner in Python3. Contribute to IBM/Drain3 development by creating an account on GitHub.
github.com
실제로 IBM에서 네트워크 중단 모니터링을 위해 사용하였으면 Masking, Persistence를 추가하고 리펙토링 및 버그 수정을 통해 보다 유용하게 Drain을 적용할 수 있다.
2) Drain3 매개변수
▷ MaxChild : Parse Tree 내부의 최대 자식 수 조절
▷ Depth : 트리의 깊이 조절(default = 4)
▷ st : 유사도 임계값(default = 0.4)
2. Drain 3 로컬 테스트
1) 로컬에 소스파일 다운(git bash 활용)
- git clone '복사한 깃헙 주소'

- examples 폴더 클릭

- test 진행할 .log파일 가져오기
아래 깃헙에서 example로그 파일 가져옴
https://github.com/logpai/loghub
GitHub - logpai/loghub: A large collection of system log datasets for log analysis research
A large collection of system log datasets for log analysis research - GitHub - logpai/loghub: A large collection of system log datasets for log analysis research
github.com

2) Online 파일 drain_stdin_demo.py 실행

파싱된 로그를 key-value값으로 추출 실행
- 출력

3) Offline 파일 drain_bigfile_demo.py 실행
- LogHub의 HDFS 데이터 샘플 2000개 사용
- 2,000개 데이터 0.21초 소요
- 고정깊이 4로 실행(depth = 4)

- 출력

4) 출력 메서드 활용
- print_tree() : 분석트리 전체 출력
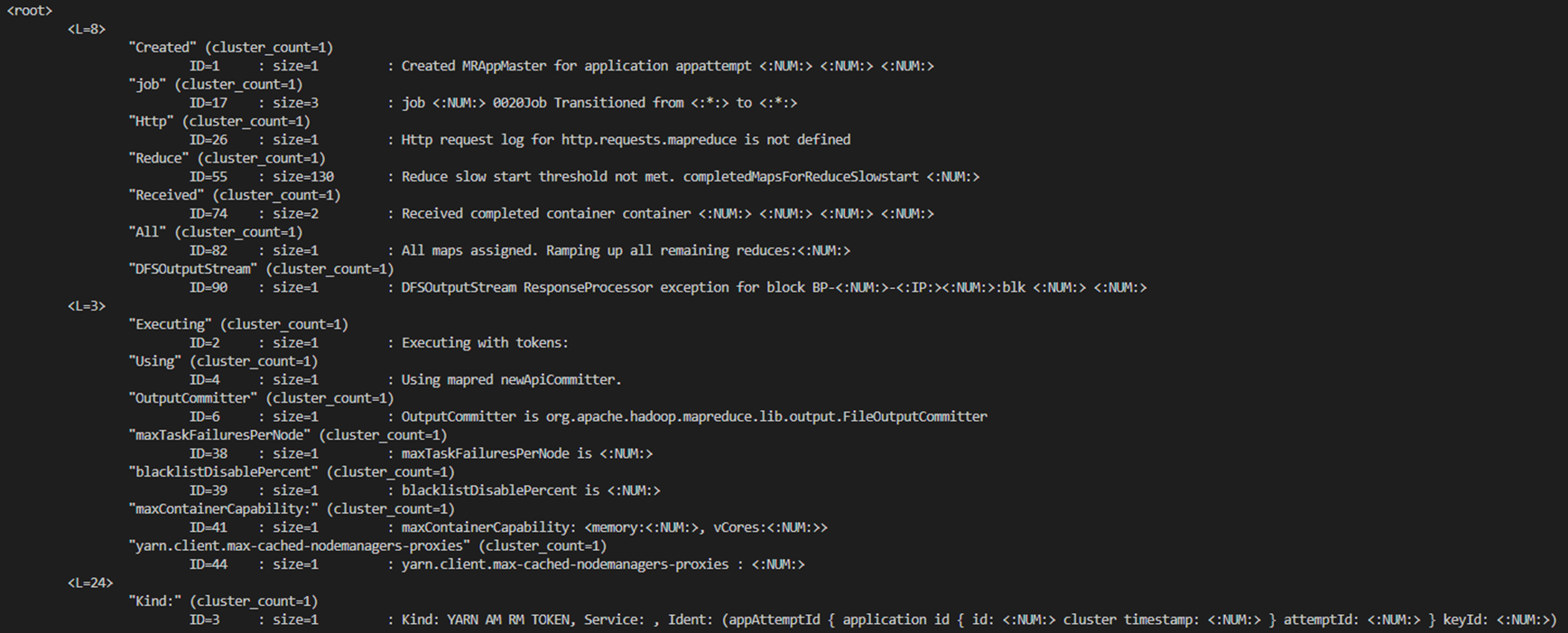
- print_node() : 분석트리에서 알고싶은 노드 출력
- 입력

- 출력

로그분석에 사용할 서비스의 로그성향을 파악하는것이 가장 우선이다.
성능만 보고 무조건 적용하기보다는 본인 서비스의 로그성향에 맞는 알고리즘을 적용하는것을 추천한다.
(다른 logparsing 기법을 모른다면 그냥 drain 사용 추천)
추후 딥러닝 기법을 활용한 로그파싱기법도 조사할 예정이다.
이상으로 자동 로그파싱기법인 Drain3에 대한 리뷰를 마침
'논문리뷰' 카테고리의 다른 글
| [논문리뷰]Swin Transformer 논문 설명 (0) | 2023.08.10 |
|---|---|
| VIT(Vision Transformer) 논문리뷰 (0) | 2023.07.24 |
| [Attention Is All You Need_논문2]Transformer _ Encoder, Decoder (0) | 2022.08.31 |
| [Attention Is All You Need_논문1]Transformer _ Embedding, Positional Encoding (0) | 2022.08.30 |
| [논문_로그파싱기술] Drain: An Online Log Parsing Approach with FixedDepth Tree 리뷰 (0) | 2022.08.04 |