![[Attention Is All You Need_논문2]Transformer _ Encoder, Decoder](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbDCSPe%2FbtrKZ0OQsn7%2Fpzs6MJpvSz5uVNojt5iL4k%2Fimg.png)
이번 포스팅은 이전에 작성한 Transformer에 이어서 Encoder, Decoder 부분에 대한 세부 기술들을 설명하려고 한다.
Tranfomer의 개요와 input값에 대한 설명은 아래 링크에서 확인가능하다.
https://zeuskwon-ds.tistory.com/87
[논문_Attention Is All You Need]Transformer _ Embedding, Positional Encoding
오늘은 자연어처리 모델중 번역 분야에서 유명한 논문인 Transformer를 정리하는 글이다. 논문 링크 : https://arxiv.org/abs/1706.03762 Attention Is All You Need The dominant sequence transduction models a..
zeuskwon-ds.tistory.com
논문 링크 : https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
Transformers _ 자연어 처리 모델
- Transformer 세부구조

4. Encoder
4.1 Multi-Head Attention
Self-Attention 설명에 앞서 병렬 Attention방법인 Multi-Head Attention을 소개한다.

위 그림과 같이 input값(Embedding + positional Encoding)이 Encoder의 입력값으로 들어오게 되면 먼저 Multi-Head Attention단계로 들어가게 된다.

이 Multi-Head Attention은 Self-Attention을 head의 수만큼 병렬로 처리한 후 Concat방식으로 합치는 방법이다.
(논문에서는 head=8로 설정)

위 그림과 같이 input값으로 4x512행렬이 들어왔을때 head=8개로 설정하고 각 head당 4x64행렬로 나눈 뒤 각각 병렬 계산을 진행한다. 그 결과값을 concat방식으로 붙여서 4x512행렬로 출력하는 방법이다.
4.2 Self-Attention
그럼 Multi-Head Attention의 각 head에서 진행되는 Self-Attention에 대해서 설명한다.
Self-Attention의 목적으로는 입력 시퀀스 특정 부분의 유사도를 계산해서 가중치를 부여하는 방법론이다. 이 때 입력값으로 Q(Query), K(Key), V(value) 3개의 값을 입력 받아 key-value로 출력한다.
여기서 Self라는 단어가 붙은 Attention메커니즘이 사용되는 이유는 유사도 측정을 자기 자신에게 수행한다는 의미이다.
즉, Query, Key, Value가 모두 동일한 입력 시퀀스 X에서 생성되는 경우 이를 Self-Attention이라고 한다.

위 그림을 보면 X는 입력단어 시퀀스이고 입력단어 가중치 행렬을 곱해서 Q(Query), K(Key), V(Value) 세 가지 값을 계산한다.
- 예시문장


위 예시 문장을 번역하면 “그 동물은 길을 건너지 않다. 왜냐하면 그것은 너무 피곤했기 때문이다.”이다. 여기서 그것(it)에 해당하는 것은 사람눈에는 당연히 동물(animal)이겠지만, 기계는 길(street)인지, 동물인지 알기 쉽지 않음
그래서 셀프 어텐션을 통해 단어 문장 내의 단어들 끼리 유사도를 구함으로써 그것(it)이 동물(animal)과 연관되었을 확률이 높다는 것을 찾아내는 방식
- Self-Attention 함수식
Self-Attention에 대한 함수식을 확인해서 구체적으로 어떻게 단어간 유사도를 구하는지 알아보자

위 식이 논문에 나와있는 Attention식이다.
이 식으로 예시문장을 들어서 계산을 진행

예시문장으로 위 문장을 사용하려고 하는데 문장을 단어(토큰)으로 나누면 9개의 토큰으로 나누어 진다는 것을 알 수 있다.

이 9개의 입력 토큰을 바탕으로 선형 레이어인 Q, K, V를 계산해서 Self-Attention의 입력값으로 넣는다.
입력값으로는 9x512 행렬값이 들어오게 되는데 이때 Multi-Head Attention로 head=8로 나누어 병렬 연산을 진행하기 때문에 1head당 9x64행렬을 input값으로 받게 된다.

그래서 식을 확인했을때 위 식의 계산과정을 거치게 되는데

먼저 Q와 Transpose(K)를 내적하게 되면 위 처럼 Q의 한 단어당 문장전체의 값을 곱하게 되고
이로인해 출력값으로 9x9행렬로 단어간 유사도가 출력되게 된다.

출력된 9x9행렬에 차원 수의 루트값을 나눠줌으로써 정규화를 진행하고 그 값에 softmax함수를 사용해서 백분율화를 진행하면서 전처리를 한다.

이렇게 전처리된 9x9행렬에 V(value)값을 곱해줌으로써 input값에 각 유사도 가중치를 곱한 결과값이 출력되게 된다.
그럼 입력값의 행렬과 출력값의 행렬은 같은 dimention을 가질 수 있다.
4.3 Add & Normalize(계층정규화)
다음으로 Attention의 출력값은 Normalize과정을 거치게 된다.

위 그림과 같이 계층정규화 과정은 Self-Attention의 입력값과 출력값을 합(sum)함으로써 한 계층에서 과도하게 데이터가 바뀌는 부분을 방지한다.
이 부분은 기울기 소실문제를 줄이기 위한 솔루션이다.
4.4 Feed Forward
다음으로 Feed Forward는 가중치를 업데이트하면서 모델 학습을 진행하는 부분이다.
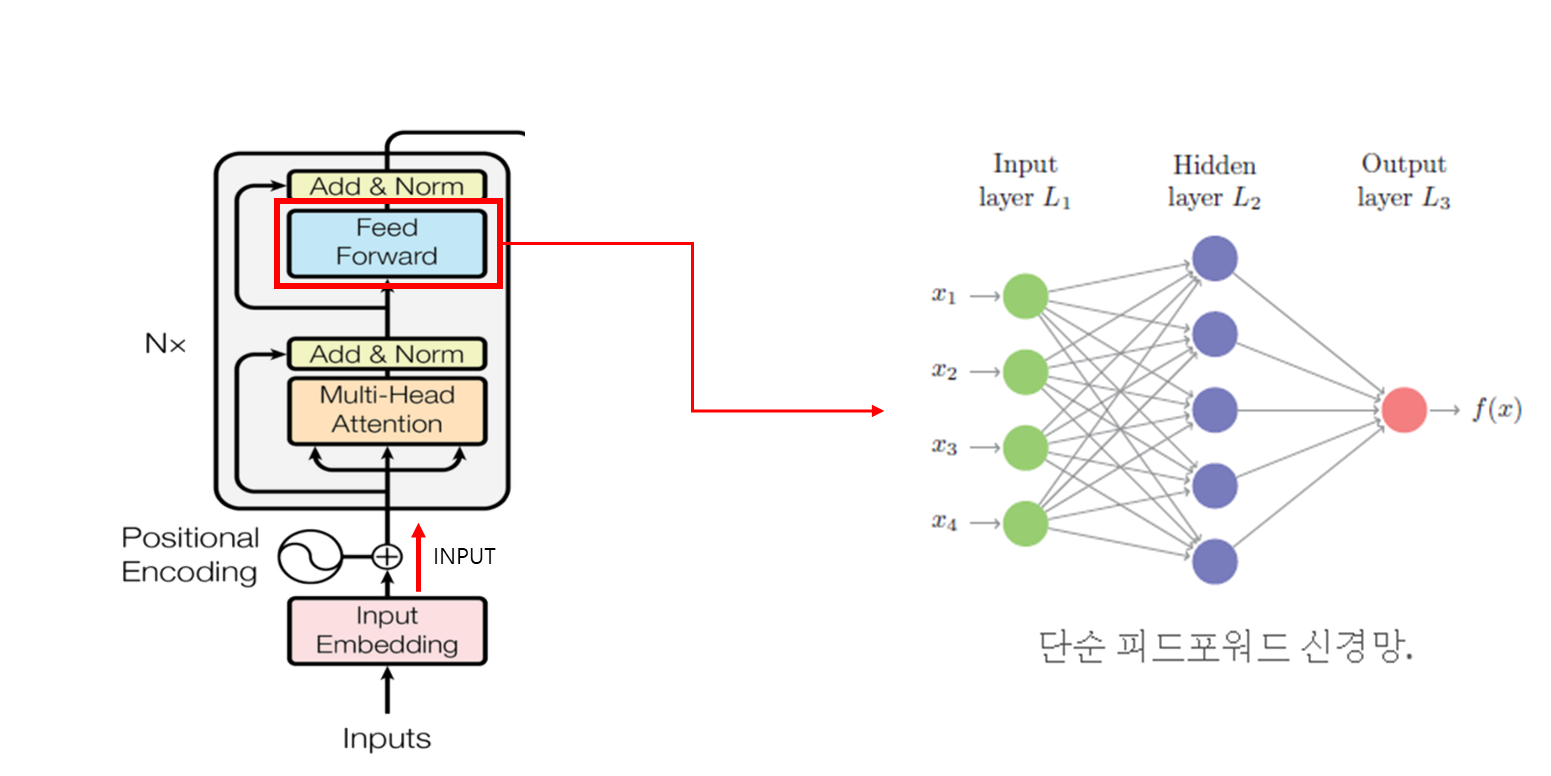
은닉층을 통해 가중치를 학습하는 공간이라고 생각하면 된다.
5. Decoder
위 Encoder과정을 N번 실행하고 출력값으로 K, V를 Decoder의 입력값으로 들어간다.
* 논문에서는 N=6

이제 Decoder의 과정을 살펴보자.
5.1 Decoder input

Encoder의 입력값으로는 문장의 토큰이 한번에 들어왔지만 Decoder의 입력값은 RNN 입력처럼 오른쪽으로 이동하면서 하나씩 단어가 입력되는 형식이다.
5.2 Masked Multihead Attention
Encoder부분에서 설명한 Self-Attention방식에서 Masking작업을 한 부분으로 생각하면 된다.
그럼 왜 Masking작업을 했을까?

그 이유로는 Decoder의 입력값으로 모델학습을 하기위한 정답이 입력되게 되는데 이때 모든 정답의 정보가 모델학습에 사용되면 과적합 되거나 모델의 성능이 떨어지는 경우가 있기때문에 masking된 일부 정보만 학습에 사용하기 위함이다.

단어간 유사도를 계산한 결과에서 뒤쪽부분을 0으로 만들어 주는 방법이다.
이렇게 만들어진 단어간 유사도가 다음 Encoder-Decoder Attention의 입력값(Qeary)으로 들어가게 된다.
다른 Decoder 부분은 Encoder와 같기 때문에 설명을 생략하고 Decoder output에 대해 설명 진행
5.3 Decoder의 output
디코더로 출력된 벡터를 단어로 바꾸는 작업으로 Linear, Softmax 방법을 사용한다.

먼저 디코더 출력을 선형 레이어로 변환하고 변환된 레이어에 Softmax함수를 사용해서 확률값으로 바꾼다.
이 확률값 중 가장 높은 확률을 가지는 단어가 출력되는 방법이다.

이것으로 Transfomer 구조에 대한 설명을 마침
정말 유명한 논문이라서 자료도 많았고 다양한 의견을 확인할 수 있어서 나름 재밌고 쉽게 파악할 수 있는 논문임
추후 Tranformer기술로 만들어진 BERT, GPT에 대한 기술도 정리해 볼 예정
출처
https://arxiv.org/abs/1706.03762
https://data-science-blog.com/blog/2021/04/07/multi-head-attention-mechanism/
https://jalammar.github.io/illustrated-transformer/
https://d2l.ai/chapter_attention-mechanisms-and-transformers/transformer.html
'논문리뷰' 카테고리의 다른 글
| [논문리뷰]Swin Transformer 논문 설명 (0) | 2023.08.10 |
|---|---|
| VIT(Vision Transformer) 논문리뷰 (0) | 2023.07.24 |
| [Attention Is All You Need_논문1]Transformer _ Embedding, Positional Encoding (0) | 2022.08.30 |
| [로그파싱기술] "Drain3" with python (2) | 2022.08.04 |
| [논문_로그파싱기술] Drain: An Online Log Parsing Approach with FixedDepth Tree 리뷰 (0) | 2022.08.04 |