![[논문_로그파싱기술] Drain: An Online Log Parsing Approach with FixedDepth Tree 리뷰](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbj9boJ%2FbtrIWNQsYDd%2Fk046e59d1yUIIfFKHqDKMK%2Fimg.png)
자동 로그파싱기술 _ Drain 알고리즘
오늘은 자동 로그파싱 기술은 Drain 알고리즘에 대해서 논문위주의 설명을 하려고 한다.
목차
- Drain
- Drain 자료
- Drain 알고리즘
- Drain 성능
1. Drain 논문, 오픈소스 자료
Drain에 관한 자료와 오픈소스 코드를 확인할 수 있는 주소
- Drain 알고리즘 논문 PDF
http://chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://jiemingzhu.github.io/pub/pjhe_icws2017.pdf
- Drain 오픈소스 자료
https://github.com/logpai/logparser/blob/master/docs/tools/Drain.md
GitHub - logpai/logparser: A toolkit for automated log parsing [ICSE'19, TDSC'18, ICWS'17, DSN'16]
A toolkit for automated log parsing [ICSE'19, TDSC'18, ICWS'17, DSN'16] - GitHub - logpai/logparser: A toolkit for automated log parsing [ICSE'19, TDSC'18, ICWS'17, DSN&...
github.com
Drain — logparser 0.1 documentation
Drain Drain is one of the representative algorithms for log parsing. It can parse logs in a streaming and timely manner. To accelerate the parsing process, Drain uses a fixed depth parse tree (See the figure below), which encodes specially designed rules f
logparser.readthedocs.io
2. Drain
Drain은 자동 로그파싱 기술이며 Offline, Online에서 모두 사용가능하지만 Online에 특화되어 있는 파싱 기법이다.
전통적인 로그파싱 기법의 문제점은 정규식에 크게 의존한다는 점인데, 이는 로그 양이 방대하고 오픈소스 플랫폼이 즐비한 현재 서비스에서 적합하지 않아 Online 파싱기법인 Drain이 제안되었다.
대표적인 특징으로 Fixed depth parse tree(고정깊이트리)를 사용한다는 점이다.
1) Drain의 장점
- 실시간으로 적시에 로그를 구조화된 템플릿으로 구분할 수 있는 Online Log Parser (실시간 스트리밍)
- 로그 구문 분석시 분석트리는 고정된 깊이 트리를 사용한다.
- 오픈소스 라이브러리이고 다른 오픈소스에 비해 성능(정확도, 속도)이 좋다.
- Online(실시간처리)방식이기 때문에 메모리 이슈가 적다.(대규모 데이터 처리 용이)
2) Drain의 목표
Drain 알고리즘의 목표는 불규칙적인 로그들을 구조화된 로그 메세지로 변환하는 것이다.

먼저 상수 부분과 변수 부분을 구분한다.
상수부분은 로그 이벤트, 변수 부분은 동적 런타임 시스템 정보를 전달하는 나머지 토큰
즉, 상수(로그 이벤트)가 동일한 로그 이벤트를 로그 그룹으로 클러스터링 하는 것이 Drain의 목표라고 할 수 있다.
3. Drain 알고리즘
Drain 논문에서 제시하는 로그 파싱기술 방법과 기술에 대한 설명을 정리
1) 정규식을 활용한 전처리
가장 먼저 실시간으로 입력되는 로그들을 분석트리에 넘겨주기 전에 정규식(Regex)으로 전처리 한다.
전처리를 하는 이유는 로그 파싱의 정확성을 향상시키기 위한 방법이다.
ex) ID, address, IP, Number 등
기존 Drain에서는 "rex"파라미터를 입력값으로 받지만 나중에 소개하는 최신버전인 Drain3에서는 마스킹작업을 통해 전처리를 실행한다.

2) 로그분석트리
이전 단계에서 전처리된 로그들이 이 로그분석트리에서 클러스터링 된다.
많은 로그 그룹을 빠르게 검색하기 위해 Fixed depth parse tree(고정깊이트리)를 설계한다.
로그 분석트리의 깊이(depth)는 파라미터로 입력을 받는다. ( default = 4)
- 깊이수준 1 : Root (= Root Node)
- 깊이수준 2 : 토큰 수 (=Internal Node)
- 깊이수준 3 : 첫 번째 로그 토큰(=Leaf Node)
- 깊이수준 4 이상 : 첫 토큰 아래의 로그 클러스터 (Log Group)
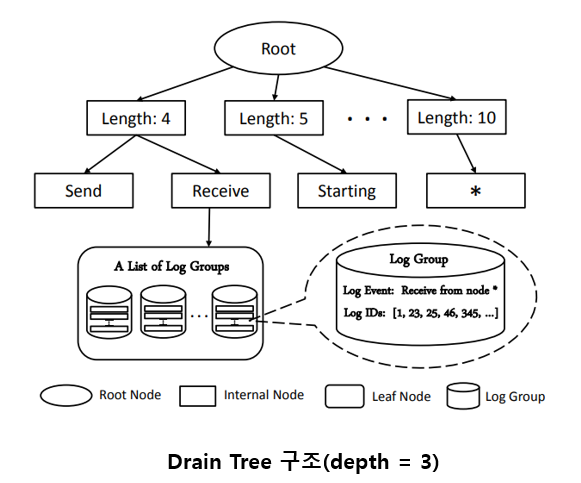
3) 유사성 계산(simSeq)
로그가 로그분석트리에 들어오면 기존에 있는 클러스터와 새로 들어온 로그간에 유사성 계산을 하게 된다.
유사성 계산은 아래의 절차와 식으로 구한다.
- 임계값(sim_th)은 파라미터로 입력받는다(default = "0.4")
- 설정한 임계값보다 유사도가 낮으면 유사하지 않다라고 판정
- 아래 식으로 로그와 로그 그룹 사이의 유사성 "simSeq"를 계산

- equ함수 합을 n으로 나눠줌으로써 유사도 백분율 측정
- 유사한 토큰의 백분율이 임계값 보다 낮으면 새로운 로그 클러스터 생성
4) Update the Parse Tree
적절한 로그 그룹이 없으면(그룹 유사도가 임계값보다 낮으면) 새로운 로그 그룹 생성
새로운 내부노드(Internal Node)와 리프노드(Leaf Node)를 추가
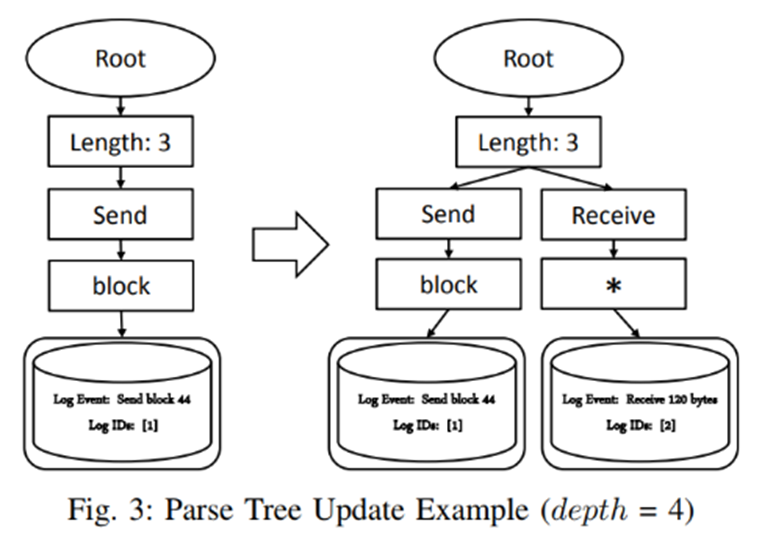
위 그림은 기존 그룹에 없는 로그 이벤트 입력시 로그분석트리가 업데이트 되는 과정을 그림으로 나타냄
ex) Log "Receive 120 bytes" 입력
- 새로 들어온 로그로 유사성을 계산하고 기존 그룹이 없기 때문에 새로운 그룹 생성
- 내부 노드와 리프노드를 추가
- 내부노드는 " * "로 인코딩 됨
4. Drain 성능
논문에 나와있는 로그 파싱기법간의 정확도 비교
컴퓨팅 성능은 아래와 같다.
* Test PC
- Server : Linux
- CPU : Intel Xeon E5-2670v2
- Ram : DDR3 128GB
1) 정확도
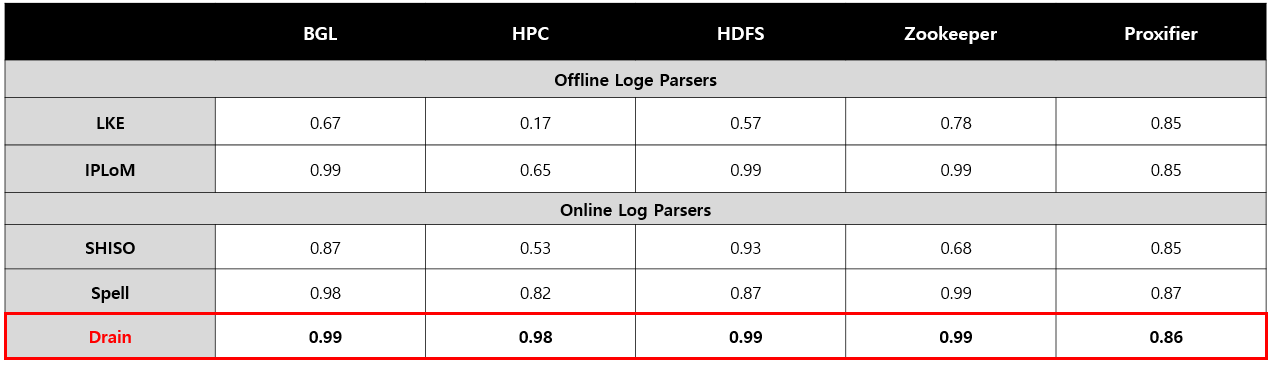
▷ 전체적인 결과로 Drain이 가장 높은 정확도
2) 속도
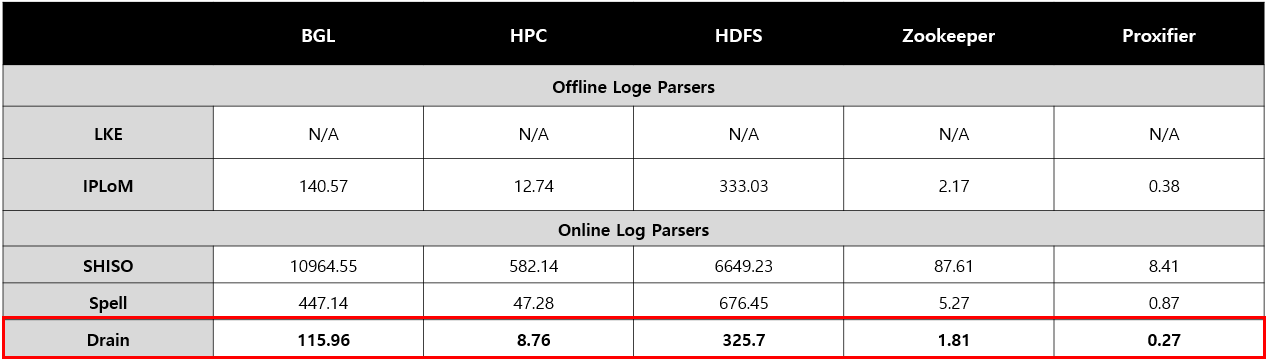
▷ Drain이 압도적으로 소요되는 시간이 짧음
3) 타 논문에 나와있는 Drain 성능
* 논문 제목 : Accurate and Efficient Log Template Discovery Technique
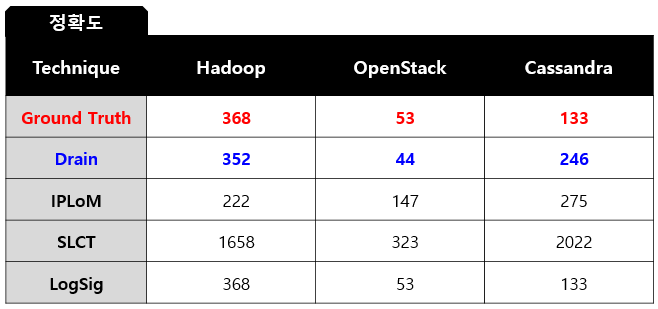
▷ LogSig : 가장 정확도가 높지만 속도가 느림
▷ Drain : 정답(Ground Truth)에 두번째로 근접
(속도에 비해 정확도 높음)
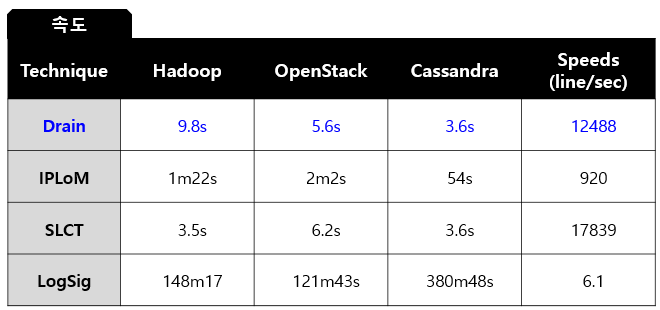
▷ SLCT : 속도가 가장 빠르지만 정확도 낮음
▷ Drain : 정확도에 비해 속도가 빠름
결론적으로 기존의 로그 파싱기법보다 Drain 기법의 성능이 좋다.
이 것으로 Drain에 대한 포스팅을 마친다
다음 포스팅으로 IBM에서 Drain기법을 기반으로 만든 Drain3에 대한 설명 진행
https://zeuskwon-ds.tistory.com/86
[로그파싱기술] Drain3
로그파싱기술 _ Drain3 이 글은 이전에 설명했던 Drain 자동로그 파싱 기법을 기반으로 IBM에서 만든 Drain3을 소개하는 글이다. Drain기법에 대한 자세한 설명을 확인하려면 아래 링크를 클릭 https://zeus
zeuskwon-ds.tistory.com
'논문리뷰' 카테고리의 다른 글
| [논문리뷰]Swin Transformer 논문 설명 (0) | 2023.08.10 |
|---|---|
| VIT(Vision Transformer) 논문리뷰 (0) | 2023.07.24 |
| [Attention Is All You Need_논문2]Transformer _ Encoder, Decoder (0) | 2022.08.31 |
| [Attention Is All You Need_논문1]Transformer _ Embedding, Positional Encoding (0) | 2022.08.30 |
| [로그파싱기술] "Drain3" with python (2) | 2022.08.04 |