
728x90

◎ Feature Engineering이란
- Feature Engineering 은 도메인 지식과 창의성을 바탕으로, 데이터셋에 존재하는 Feature들을 재조합하여 새로운 Feature를 만드는 것이다.

위 그림처럼 2개의 feature를 가진 데이터가 있다면,
해당 feature를 조합하여 (+) 새로운 feature를 만들어 낸 다음, 이를 분석에 사용 할 수 있을 것이다.
통계 분석 혹은 머신러닝, 더 나아가 딥러닝까지 대부분의 분석은 데이터에 있는 패턴을 인식하고, 해당 패턴들을 바탕으로 예측을 하기 때문에, 더 좋은 성능을 위하여 더 새롭고, 더 의미있는 패턴을 제공하는 것이 궁극적인 Feature engineering의 목적이다.
- 데이터 불러오기
import pandas as pd
df = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/kt%26g/kt%26g.csv')
df
▷ Feature Engineering

위 데이터를 기반으로 새로운 투자지표
- "J-value" = ROE + ROA
df['j-value'] = df['ROE(%)'] + df['ROA(%)']
df
◎ String Replace
- 문자형으로 되어있는 데이터를 숫자형으로 변환해서 평균, 합계 등을 구한다.
- 문자형으로 " , "가 포함되어있으면 제거후 변환
string variable.replace(“삭제할 글자“, "") 의 형태로 사용 ( 공백으로 대치 )
String = '37,870'
String = int(String.replace(',',''))<출력>
37870
- 함수화
문자열을 칼럼단위로 전체를 변경할때는 함수화 필요
# 입력된 문자열에 대해서 같은 작업을 하는 함수 작성
def toInt(string):
return int(string.replace(',',''))
toInt('37,870')<출력>
37870
◎ Apply
데이터의 모든 문자열에 대해서 일일히 toInt함수를 반복을 하지 않고 apply함수를 사용하면 칼럼 전체에 적용가능
- apply 사용법
- [새로운칼럼] = [적용칼럼].apply(함수name)
df['자산2'] = df['자산'].apply(toInt)
df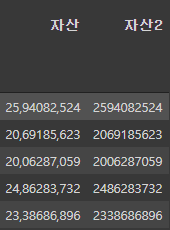
apply함수를 사용하는 법은 생각보다 데이터 전처리를 할 때 자주 사용하기 때문에 방법을 익혀놓으면 좋은 무기가 된다.
728x90
'Python' 카테고리의 다른 글
| [Python] 데코레이터 제대로 알고 사용하기 (1) | 2022.04.12 |
|---|---|
| [colab] 코랩에서 pandas로 데이터 불러오기(csv,json) (0) | 2022.02.20 |
| pandas기초 _ 데이터 전처리(합치기(concat, merge), Groupby) (0) | 2021.05.19 |
| pandas기초 _ 데이터 전처리(EDA란, Data Preprocessing) (0) | 2021.05.15 |