

◎ Pandas로 데이터 셋을 불러오기
- Description을 통해 데이터셋에 대한 정보를 파악한다.
- 행과 열의 수
- 열에 헤더가 있는지 ("데이터 이름"이 있는지?)
- 결측 데이터 (Missing data)가 있는지 확인
- 원본의 형태를 확인하기 : 우리가 기대하던 형태가 아닐 수도 있다.
데이터셋을 확인하는 방법. (Colab 에서 read_csv)
import pandas as pd
#
ktng_data_url = 'https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/kt%26g/kt%26g_0.csv'
# pandas라이브러리의 read_csv로 csv파일 변수에 저장
df = pd.read_csv(ktng_data_url)
df.head()
칼럼 추가
위 데이터 확인하면 1열이 칼럼으로 지정되어있기 때문에 칼럼추가 필요
column_headers = ['분기','매출액','영업이익','영업이익(발표기준)','세전계속사업이익',
'당기순이익','당기순이익(지배)','당기순이익(비지배)','자산총계','부채총계',
'자본총계','자본총계(지배)','자본총계(비지배)','자본금','영업활동현금흐름',
'투자활동현금흐름','재무활동현금흐름','영업이익률','순이익률','ROE(%)',
'ROA(%)','부채비율','자본유보율','EPS(원)','PER(배)']
df = pd.read_csv(ktng_data_url, names = column_headers)
df.head()
◎ EDA (Exploratory Data Analysis)
EDA란, 데이터 분석에 있어서 매우 중요한, 초기 분석의 단계를 의미하며
- 시각화 같은 도구를 통해서 패턴을 발견하거나
- 데이터의 특이성을 확인하거나
- 통계와 그래픽 (혹은 시각적 표현)을 통해서 가설을 검정하는 과정 등을 포함한다.
EDA의 방법은 크게 2가지 (Graphic, Non-Graphic) 으로 나눠질 수 있으며
- Graphic : 차트 혹은 그림 등을 이용하여 데이터를 확인하는 방법이다.
- Non-Graphic : 그래픽적인 요소를 사용하지 않는 방법으로, 주로 Summary Statistics를 통해 데이터를 확인하는 방법이다.
- Uni - Non Graphic
Sample Data의 Distribution을 확인하는 것이 주목적이다.
Numeric data의 경우 summary statistics를 제일 많이 활용하는데요. 이에는
- Center (Mean, Median, Mod)
- Spread (Variance, SD, IQR, Range)
- Modality (Peak)
- Shape (Tail, Skewness, Kurtosis)
- Outliers 등을 확인합니다.
Categorical data의 경우 occurence, frequency, tabulation등을 할 수 있다.
Statistic / CollegeH&SSMCSSCSOtherTotal
| Statistic / College | H&SS | MCS | SCS | Other | Total |
| Count | 5 | 6 | 4 | 5 | 20 |
| Propotion | 0.25 | 0.3 | 0.2 | 0.25 | 1 |
| Percent | 25% | 30% | 20% | 25% | 100% |
- Uni - Graphic
Histogram 혹은 Pie chart, Stem-leaf plot, Boxplot, QQplot 등을 사용한다.
그러나 만약 값들이 너무 다양하다면, Binning, Tabulation등을 활용 할 수도 있다.
◎ Data Preprocessing (데이터 전처리)
수집한 데이터들을 사용하기 전에 가공하는 작업
- Cleaning
- Integration
- Transformation
- Reduction
Garbage In Garbage Out
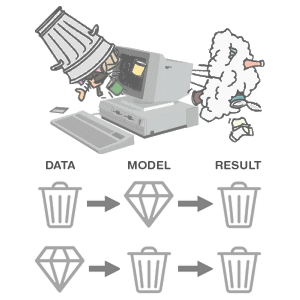
- Cleaning
noise 를 제거하거나, inconsistency 를 보정하는 과정을 의미한다.
데이터의 정확도, 완성도, 일관성, 신뢰성과 같은 값이 빠져있거나, 잘못 입력되거나 혹은 일관성을 가지지 않는
데이터들을 제거 / 보정 하는 과정들이 포함되어 있다.
- Integration
여러개로 나누어져 있는 데이터들을 분석하기 편하게 하나로 합치는 과정을 의미한다.
예시로 merge와 concate가 있다.
- Transformation
데이터의 형태를 변환하는 작업으로, scaling이라고 부르기도 한다.
예시로 정규화(normalize)가 있다.
- Reduction
데이터를 의미있게 줄이는 것을 의미하며, dimension reduction과 유사한 목적을 갖는다.
예시로 PCA가 있다.
데이터 전처리는 데이터를 활용하는 분야의 가장 기초이다.
기초부터 확실히 알고가야할 것이다.
'Python' 카테고리의 다른 글
| [Python] 데코레이터 제대로 알고 사용하기 (1) | 2022.04.12 |
|---|---|
| [colab] 코랩에서 pandas로 데이터 불러오기(csv,json) (0) | 2022.02.20 |
| pandas기초 _ 데이터 전처리(합치기(concat, merge), Groupby) (0) | 2021.05.19 |
| pandas기초 _ Feature Engineering(String replace, Apply 사용법) (0) | 2021.05.18 |