![[Docker] Linux(CentOS) Hadoop 클러스터 구성하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcknKfN%2FbtrCdIJX8f1%2FAAAAAAAAAAAAAAAAAAAAABmtN9QE-QpmIQQvz1rSUF2JB_EC-ICsFbhgmyvlrPCD%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3Dzz7384jvwNwgP2gYP8Qdd76GxnM%253D)
이번 포스팅에서는 Docker로 Hadoop 클러스터를 구성해보겠다.
도커로 하둡클러스터 구성한 환경은 리눅스(CentOS)에서 진행했다.
1. Docker-Hadoop repository 구성
하둡 클러스터로는 big-data-europe에서 만든 하둡이미지를 사용한다.
(아래 링크 참조)
https://github.com/big-data-europe/docker-hadoop.git
GitHub - big-data-europe/docker-hadoop: Apache Hadoop docker image
Apache Hadoop docker image. Contribute to big-data-europe/docker-hadoop development by creating an account on GitHub.
github.com
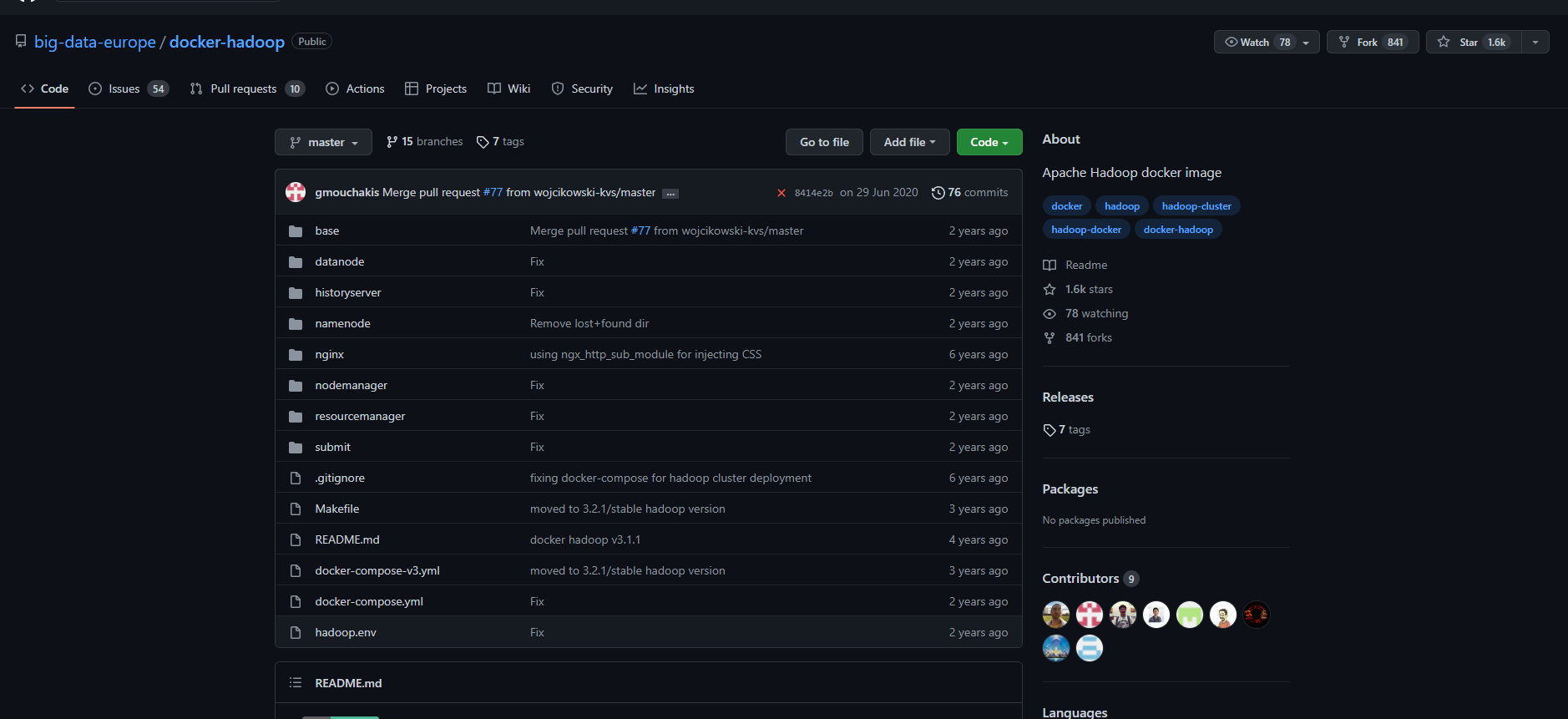
- 해당 레파지토리 로컬로 가져오기
git clone https://github.com/big-data-europe/docker-hadoop.git
로컬에 docker-hadoop이 설치되면 성공
- 해당 레파지토리로 이동
cd docker-hadoop
docker-hadoop폴더는 위 사진처럼 구성되고 test, simple-text는 테스트를 위해 내가 따로 만든 파일이라서 없는게 당연하다.
- docker-compose.yml 확인
- NameNode - 9870, 9871
- DataNOde - 9864
- ResourceManager - 8088
vi docker-compose.yml
원래 namenode는 기본적으로 9870,9000 포트를 사용하지만 나는 9000 포트를 사용중이기 때문에 9871포트로 할당했다.
datanode에서 SERVICE_PRECONDITION 환경변수를 통해서 namenode와 포트번호를 지정했다.
또, namenode와 datanode의 volumes 경로를 제대로 설정해줘야 함.
- vi편집기 나가기
:wq- docker-compose up 으로 도커 실행하기
docker-compose up -d- 도커 실행 확인하기
docker ps
총 5개의 도커가 실행이 되면 성공한것이다.
만약 도커를 내리고 싶다면 아래 코드를 실행하면 된다.
docker-compose down
2. 하둡 클러스터 구성 url 접속
- NameNode - localhost:9870
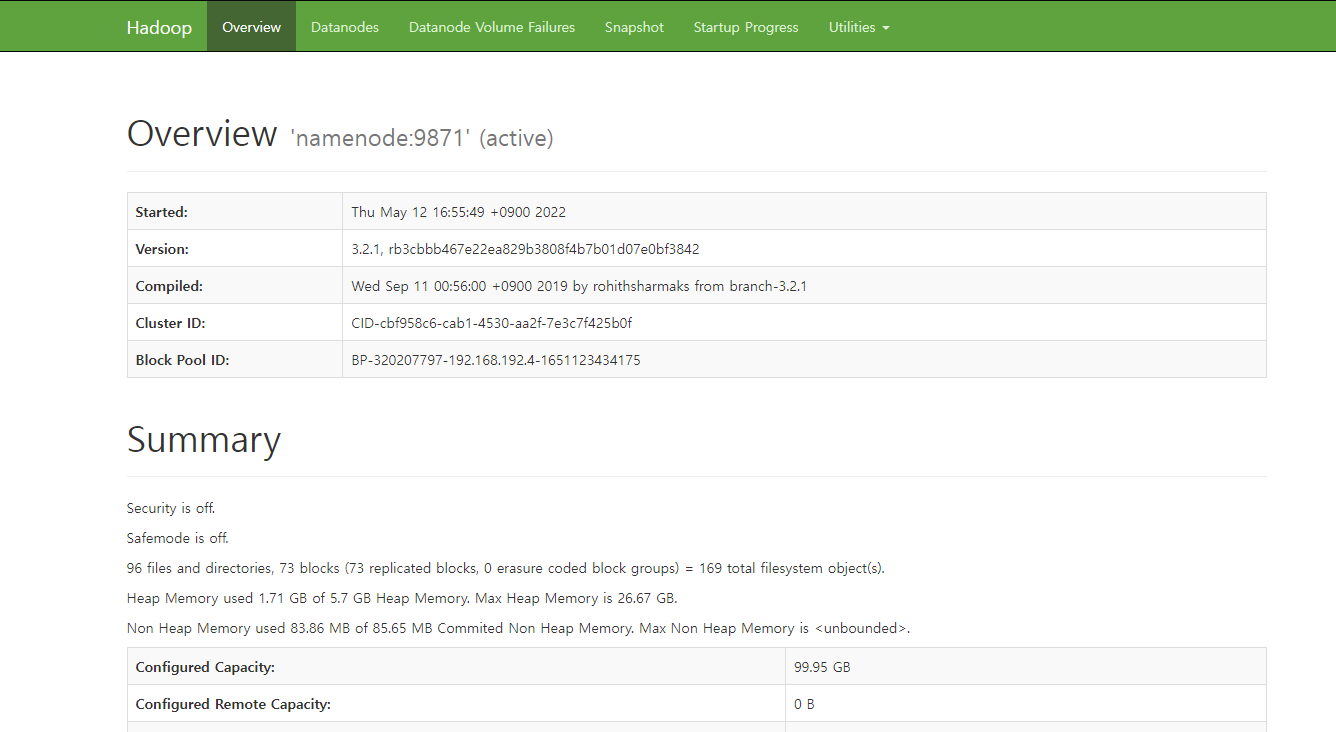
하둡 데이터에 대한 디스크 정보를 볼 수 있는 UI이다.
이름은 Namenode 데이터 UI 이지만 datanode의 데이터도 확인가능하다.
- DataNode - localhost:9864
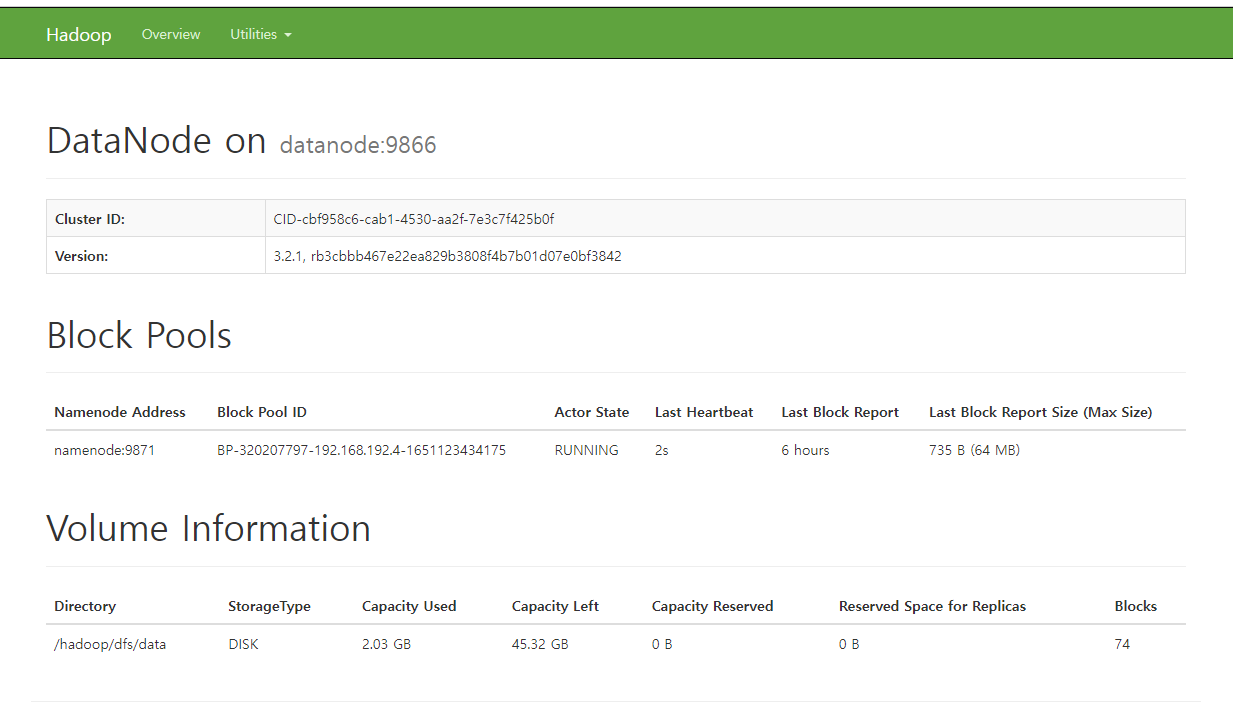
이 포트보다 9870을 쓰는게 더 좋을 듯
- ResourceManager - 8088
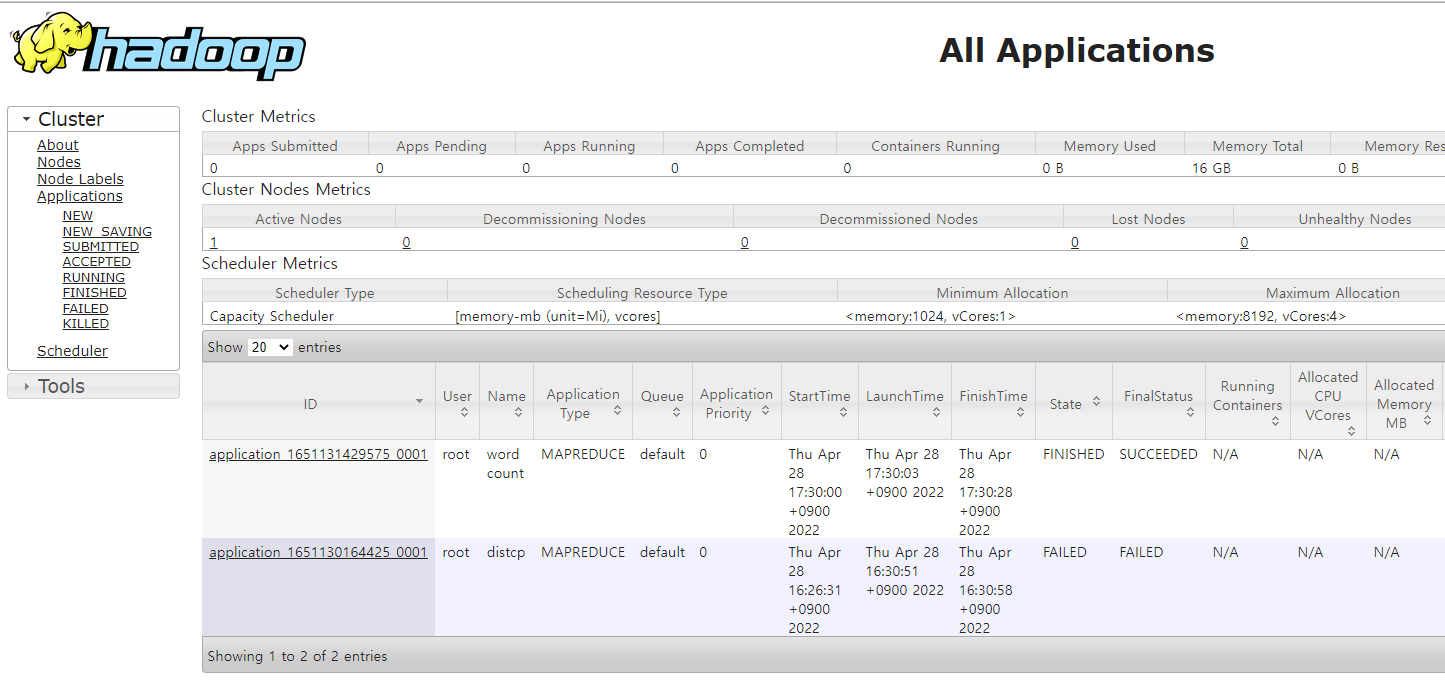
Hadoop MapReduce 역할로, 병렬처리를 위해 존재하고 Scheduler와 Application Manager로 구성되어 있다.
자세한 설명은 아래 하둡 HDFS 설명 포스팅에서 확인하면 된다.
https://zeuskwon-ds.tistory.com/71
[hadoop] docker-hadoop 컨테이너 설명
이번 포스팅에서는 Hadoop 클러스터의 컨테이너에 대해서 알아보자. 만약 docker로 Hadoop 클러스터를 구성하는 방법이 궁금하면 아래 포스팅을 참고하자 https://zeuskwon-ds.tistory.com/68?category=1023021 [D..
zeuskwon-ds.tistory.com
'Server&Network&클라우드' 카테고리의 다른 글
| [AWS-S3] S3 CLI 명령어 _기본 (0) | 2024.02.21 |
|---|---|
| [AWS-S3] S3 버킷 알아보기 (0) | 2024.02.19 |
| [클라우드] Amazon EC2 인스턴스 유형 정리 (1) | 2024.01.04 |
| [Docker] Linux(CentOS) Docker 간단 설치 (0) | 2023.03.09 |
| [Docker] docker-hadoop 컨테이너 설명 (0) | 2022.05.17 |