
신입 연구 과제로 MNIST 손글씨 분류 과제를 진행했는데 과제로 VGGNet 구조로 Layer를 쌓아서 모델을 구현해보았습니다.
그리고 Keras에 내장된 VGG과 ResNet 전이학습 모델을 가져와서 성능을 비교해보는 코드도 작성해보았습니다.
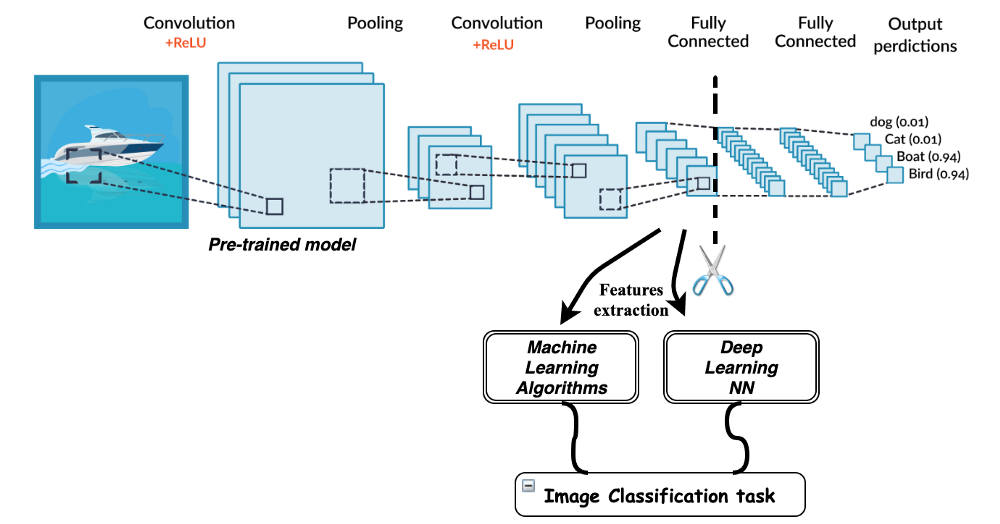
먼저 CNN알고리즘에 대한 설명을 간략하게 정리하고 코드로 구현하겠습니다.
CNN 알고리즘 개념
신경망 자체와 마찬가지로 CNN은 생물학, 특히 고양이의 시각 피질의 수용 영역(receptive field)에서 영감을 받았습니다. 이미지는 2차원으로 구성된 데이터이기 때문에 이를 1차원으로 나열하면 이미지의 특성을 알아차리기 어려운 문제가 있었는데 이러한 문제를 해결하기 위해 개발된 모델이 CNN모델입니다.
기본적으로 CNN알고리즘은 이전의 일반적인 DNN, 네트워크와 달리 필터(Convolution)를 사용하는데 이러한 방법으로 시각적 접근 방식을 모방합니다. 컨볼루션은 한 함수가 다른 함수를 수정하는 방법을 보여주는 세 번째 함수를 생성하는 두 함수에 대한 연산입니다. 컨볼루션에는 교환 성, 연관성, 분배 성 등 다양한 수학적 속성이 있습니다. 컨볼루션을 적용하면 입력의 "모양(shape)"이 효과적으로 변환됩니다.
"컨볼 루션"이라는 용어는 세 번째 공동 함수(Weight Sharing)를 계산하는 프로세스와 이를 적용하는 프로세스를 모두 지칭하는 데 사용됩니다. 우리의 맥락에서, 실제 동물의 시야에서 피질의 수용 영역으로의 매핑과 느슨하게 유사한 애플리케이션으로 생각하는 것이 더 유용합니다.
CNN모델의 구성을 살펴보겠습니다.

위 그림은 가장 기본적인 모델로 Convolutional Layer와 Pooling Layer 두개를 연달아 놓은 후 그 데이터를 1차원으로 만들어주고 Fully Connected Layer로 타겟 Layer의 Class 수에 맞게 출력 값을 설정해준 후 softmax와 같은 활성 함수를 통과시키는 모델입니다.
2D - Convolution
- Convolution
이미지의 노란색 부분으로 변하는 부분이 Convolution filter와 만나는 부분입니다.
- Filter: 가중치 (weights parameters)의 집합으로 이루어져 가장 작은 특징을 잡아내는 창
- Stride: 필터(filter)를 얼만큼씩 움직이며 이미지를 볼 지 결정하는 수 (예) Stride가 1이면 한 칸씩 이동하며, 누락 없이 모든 것을 본다면, stride가 2 이면 한 칸씩 건너뛰면서 Filter를 적용하게 되고, 띈 만큼 다음 레이어의 데이터의 수가 줄어듭니다.
- Padding: Zeros(또는 다른 값)을 이미지의 외각(가장자리)에 배치하여 conv를 할 때 원래 이미지와 같은 데이터의 수를 갖을 수 있도록 도와줌 (Stride = 1일 때)
CNN알고리즘 활용 MNIST 손글씨 분류 코드
- 필요 라이브러리 import
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from keras.models import Sequential
from keras.callbacks import EarlyStopping
from keras.layers import Dense, Conv2D, MaxPool2D , Flatten,MaxPooling2D,Dropout
from keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import datasets, layers, models, losses, Model- Keras에서 MNIST데이터 가져와서 Trian, Test분리
mnist = tf.keras.datasets.mnist
# 가져온 mnist를 train과 test 데이터로 분리
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 분리된 데이터를 rgb값 255로 나눠서 0과 1사이의 값으로 변경
x_train = tf.pad(x_train, [[0, 0], [2,2], [2,2]])/255
x_test = tf.pad(x_test, [[0, 0], [2,2], [2,2]])/255
# 배열의 형상을 변경해서 차원 수를 3으로 설정
# # 전이학습 모델 input값 설정시 차원을 3으로 설정해줘야 함
x_train = tf.expand_dims(x_train, axis=3, name=None)
x_test = tf.expand_dims(x_test, axis=3, name=None)
x_train = tf.repeat(x_train, 3, axis=3)
x_test = tf.repeat(x_test, 3, axis=3)
# train, test 데이터 shape 확인
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)(60000, 32, 32) (60000,) (10000, 32, 32) (10000,)
- Train데이터의 이미지와 라벨값이 정확한지 데이터 확인
import matplotlib.pyplot as plt
# train데이터와 label데이터가 정확한지 확인하기 위해 15개의 데이터를 시각화로 확인
# 문제 없음
plt.figure(figsize=(10, 10))
c = 0
for x in range(5):
for y in range(3):
plt.subplot(5,3,c+1)
plt.imshow(x_train[c], cmap='gray')
c+=1
plt.show()
print(y_train[:15])
[5 0 4 1 9 2 1 3 1 4 3 5 3 6 1]
# 문제없음 #
- 기본 CNN구조로 성능 검정
# 베이스라인 모델로 성능 검정을 위해 임의로 만들어보는 CNN모델
# Conv, Pooling 레이어를 추가한 후 Dense 레이어가 들어간 일반적인 모델
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(input_shape=(32, 32, 3), kernel_size=3, filters=64),
tf.keras.layers.MaxPool2D(pool_size=(2,2), strides=(1,1)),
tf.keras.layers.Conv2D(input_shape=(32, 32, 3), kernel_size=3, filters=32),
tf.keras.layers.MaxPool2D(pool_size=(2,2), strides=(1,1)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax'),
])
# 옵티마이저(optimizer)와 손실함수(loss)를 설정하고 정확도 매트릭스가 나오게 컴파일
# optimizer -> 'adam'
# loss -> sparse_categorical_crossentropy
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 모델의 모습을 표로 출력
model.summary()
# 위의 레이어를 가진 모델로 5번 학습시킴
print(model.fit(x_train, y_train, epochs=5))
# 검증을 해봄
print(model.evaluate(x_test, y_test))
생각보다 높은 성능을 보여서 굳이 VGGNet 구조로 할 필요 없지만 비교해보고 공부하기 위해 아래에서 구현을 해보았습니다.
VGGNet 구조를 사용해서 CNN알고리즘을 구현
- 기본 VGG구조로 구현(Convolution을 하고 곂쳐서 Covolution을 하는 알고리즘)
# VGGNet 구조로 CNN모델 구현
model_vgg = tf.keras.models.Sequential([
# 첫번째 convolution
# conv(filters = 64) -> conv(filters = 64) -> fool(pool_size = 2)
tf.keras.layers.Conv2D(input_shape=(32, 32, 1), kernel_size=3,padding="same", filters=64),
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=64),
tf.keras.layers.MaxPool2D(pool_size=(2,2),padding="same", strides=(2,2)),
# 두번째 convolution
# conv(filters = 128) -> conv(filters = 128) -> fool(pool_size = 2)
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=128),
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=128),
tf.keras.layers.MaxPool2D(pool_size=(2,2),padding="same", strides=(2,2)),
# 데이터의 차원을 변환하기 위해 flatten진행
tf.keras.layers.Flatten(),
# vgg알고리즘에 layer를 추가
tf.keras.layers.Dense(4096, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1000, activation='relu'),
# tf.keras.layers.Dropout(0.5),
# 타겟 class가 10이기 때문에 출력 라벨값도 10으로 고정
tf.keras.layers.Dense(10, activation='softmax'),
])
# 옵티마이저와 손실함수를 설정하고 정확도 매트릭스가 나오게 컴파일
# optimizer -> 'adam'
# loss -> sparse_categorical_crossentropy
model_vgg.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 모델의 모습을 표로 출력
model_vgg.summary()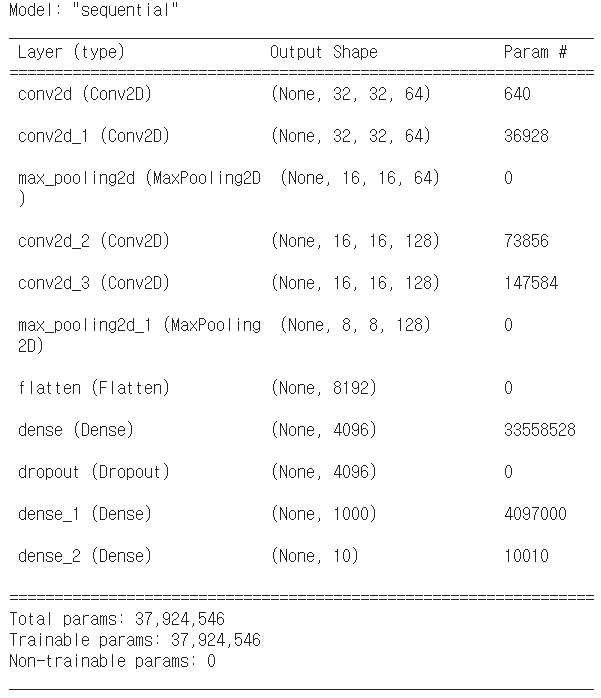
# 과적합으로 loss가 올라가면 멈추도록 earlystop기능 사용
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)
# 위의 레이어를 가진 VGGNet모델로 5번 학습시킴
print(model_vgg.fit(x_train, y_train, batch_size = 100, epochs=10,verbose=1, callbacks=[callback], validation_data=(x_test, y_test)))
# test데이터로 검증을 해봄
print(model_vgg.evaluate(x_test, y_test))
간단한 기본 VGGNet모델로도 높은 성능을 나타낸다.
전이학습 (Transfer Learning)
기존(내 목적과는 다른) 데이터로 학습된 네트워크를 재사용 가능하도록하는 라이브러리입니다.
- VGG16 구조로 CNN모델 구현
# VGG16 구조로 CNN모델 구현
model_vgg = tf.keras.models.Sequential([
# 첫번째 convolution
# conv(filters = 64) -> conv(filters = 64) -> fool(pool_size = 2)
tf.keras.layers.Conv2D(input_shape=(32, 32, 3), kernel_size=3,padding="same", filters=64),
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=64),
tf.keras.layers.MaxPool2D(pool_size=(2,2),padding="same", strides=(2,2)),
# 두번째 convolution
# conv(filters = 128) -> conv(filters = 128) -> fool(pool_size = 2)
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=128),
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=128),
tf.keras.layers.MaxPool2D(pool_size=(2,2),padding="same", strides=(2,2)),
# 두번째 convolution
# conv(filters = 256) -> conv(filters = 256) -> fool(pool_size = 2)
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=256),
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=256),
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=256),
tf.keras.layers.MaxPool2D(pool_size=(2,2),padding="same", strides=(2,2)),
# 두번째 convolution
# conv(filters = 512) -> conv(filters = 512) -> fool(pool_size = 2)
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=512),
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=512),
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=512),
tf.keras.layers.MaxPool2D(pool_size=(2,2),padding="same", strides=(2,2)),
# 두번째 convolution
# conv(filters = 512) -> conv(filters = 512) -> fool(pool_size = 2)
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=512),
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=512),
tf.keras.layers.Conv2D(kernel_size=3,padding="same", filters=512),
tf.keras.layers.MaxPool2D(pool_size=(2,2),padding="same", strides=(2,2)),
# 데이터의 차원을 변환하기 위해 flatten진행
tf.keras.layers.Flatten(),
# vgg알고리즘에 layer를 추가
tf.keras.layers.Dense(4096, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1000, activation='relu'),
# tf.keras.layers.Dropout(0.5),
# 타겟 class가 10이기 때문에 출력 라벨값도 10으로 고정
tf.keras.layers.Dense(10, activation='softmax'),
])
# 옵티마이저와 손실함수를 설정하고 정확도 매트릭스가 나오게 컴파일
# optimizer -> 'adam'
# loss -> sparse_categorical_crossentropy
model_vgg.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 모델의 모습을 표로 출력
model_vgg.summary()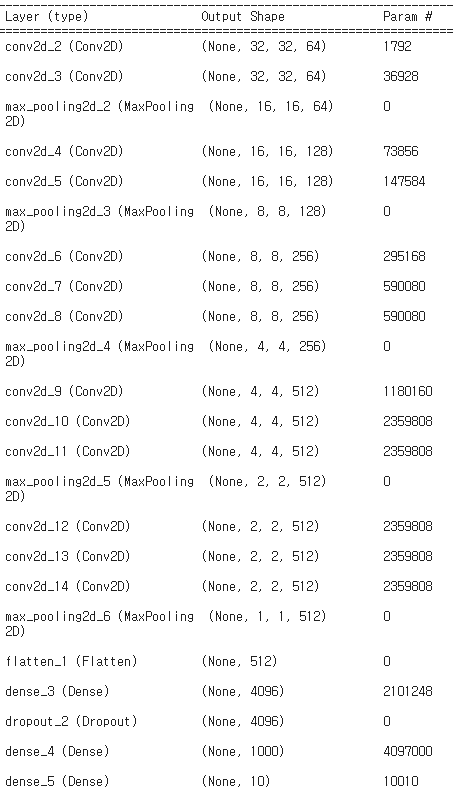
# 과적합으로 loss가 올라가면 멈추도록 earlystop기능 사용
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)
# 위의 레이어를 가진 VGGNet모델로 5번 학습시킴
print(model_vgg.fit(x_train, y_train, batch_size = 100, epochs=10,verbose=1, callbacks=[callback], validation_data=(x_test, y_test)))
# test데이터로 검증을 해봄
print(model_vgg.evaluate(x_test, y_test))

epoch 5까지는 높은 성능으로 학습이 되다가 갑자기 loss값이 올라가면서 정확도가 0.11로 떨어지는 문제가 발생하네요
Keras VGG16 전이 학습 사용
- 직접 만든 VGG알고리즘과 비교해보기 위해 keras라이브러리에 저장되어 있는 VGG16 전이 학습모델로 결과 확인
# keras.VGG16 전이학습모델 가져오기
model_VGG16 = tf.keras.applications.VGG16(weights = 'imagenet', include_top = False,input_shape = (32,32,3))
for layer in model_VGG16.layers:
layer.trainable = False
# 위의 VGG16의 구조와 동일하게 레이어를 구성
x = layers.Flatten()(model_VGG16.output)
x = layers.Dense(4096, activation='relu')(x)
x = layers.Dropout(0.2)(x)
x = layers.Dense(1000, activation='relu')(x)
predictions = layers.Dense(10, activation = 'softmax')(x)
# 옵티마이저와 손실함수를 설정하고 정확도 매트릭스가 나오게 컴파일
# optimizer -> 'adam'
# loss -> sparse_categorical_crossentropy
head_model = Model(inputs = model_VGG16.input, outputs = predictions)
head_model.compile(optimizer='adam', loss=losses.sparse_categorical_crossentropy, metrics=['accuracy'])
head_model.summary()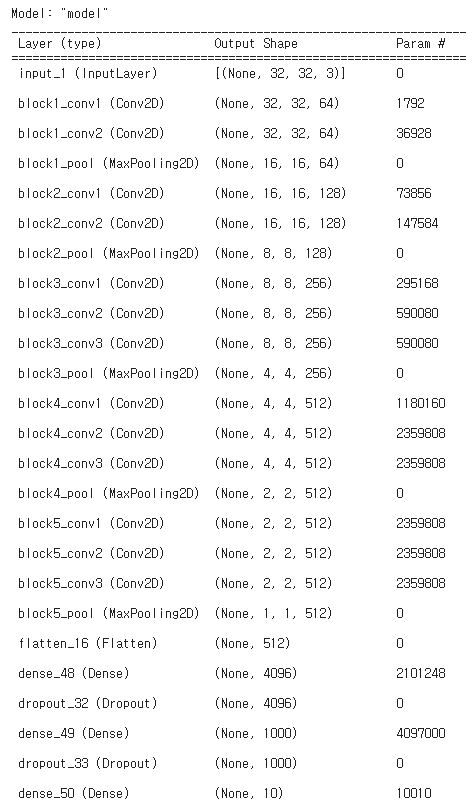
# 모델을 epochs = 40으로 학습하고 test데이터로 정확도 확인
history = head_model.fit(x_train, y_train, batch_size=64, epochs=40)
head_model.evaluate(x_test, y_test)
전이 학습모델로 학습을 하면 높은 성능을 나타내는데 내가 직접 Layer를 쌓은 모델은 왜 Loss값이 저렇게 많이 나오는지 더 공부해야겠네요
ResNet구조로 CNN모델 구현(그 중 가장 좋은 성능을 나타내는 ResNet152를 사용)
- 마이크로소프트에서 개발한 알고리즘인 ResNet모델은 2015년 ILSVRC에서 우승을 차지한 검증된 전이 학습 모델
- ResNet의 기본구조가 VGG-19의 구조를 뼈대로 하는게 흥미롭다
- ResNet152의 구조는 너무 깊은 layer를 갖고 있기 때문에 직접 구현은 못하고 전이 학습 모델을 가져와서 사용
# keras.resnet152 전이학습모델 가져오기
model_Res = tf.keras.applications.ResNet152V2(weights = 'imagenet', include_top = False,input_shape = (32,32,3))
for layer in model_Res.layers:
layer.trainable = False
# 전이학습모델에서 Flatten 후 출력 CLASS 정하기
x = layers.Flatten()(model_Res.output)
predictions = layers.Dense(10, activation = 'softmax')(x)
# 모델 학습 후 summary로 확인
head_model_res = Model(inputs = model_Res.input, outputs = predictions)
head_model_res.compile(optimizer='adam', loss=losses.sparse_categorical_crossentropy, metrics=['accuracy'])
head_model_res.summary()
layer가 152층이어서 그런가 summary가 어마어마하게 길다..
# 모델을 epochs = 40으로 학습하고 test데이터로 정확도 확인
history = head_model_res.fit(x_train, y_train, batch_size=256, epochs=40)
head_model_res.evaluate(x_test, y_test)
오히려 더 성능이 떨어지는 결과가 나오는데 층이 많다고 무조건 좋은 것이 아니라는 생각이 들었고 간단한 분류 문제는 모델이 무거우면 오히려 성능이 떨어지는 결과가 나올 수 있습니다.
아래를 클릭하면 자세한 설명과 더 많은 전이학습모델을 확인할 수 있습니다.
'DataScience > ComputerVision' 카테고리의 다른 글
| YOLOv5 코드 구현 _ Traffic Sign Dataset (1) | 2023.01.06 |
|---|---|
| One-Step Object Detection _ YOLOv5 (1) | 2023.01.06 |
| ObjectDetection이란? 기술, 알고리즘 연혁 알아보기 (0) | 2023.01.04 |