
◎ T-검정이란?
T- 검정은 모집단의분산이나표준편차를 알지 못할 때, 표본으로부터 추정된 분산이나 표준편차를 이용하여 두 모집단의 평균의 차이를 알아보는 검정 방법이다. 집단의 수는 최대 2개까지 비교 가능하며 3개 이상인 경우 분산분석(ANOVA)를 사용한다.
▷ T-검정의 가정
1)종속변수가 양적 변수일 때
2)모집단의 분산이나 표준편차를 알지 못할 때
3)모집단의 분포가 정규분포일 때
- 가정
1)독립성: 독립변수의 그룹 군은 서로 독립적 이여야 한다.
2)정규성: 독립변수에 따른 종속변수는 정규분포를 만족해야한다.
3)등분산성: 독립변수에 따른 종속변수 분포의 분산은 각 군마다 동일하다.

즉 t-test는특정한 조건에서그룹의 평균을 비교하기 위한 가설검정 방법이라는 것 입니다.
◎ Type of Error
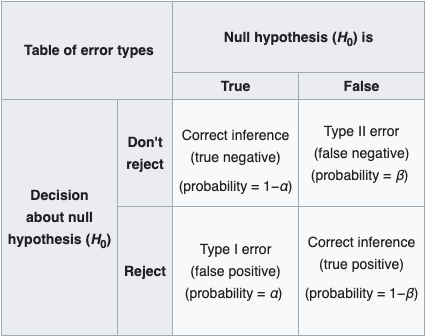
- Type 1 error : 실제로는 귀무가설을 기각하지 않는데 귀무가설을 기각하는 경우
- Type 2 error : 실제로는 귀무가설을 기각하는데 귀무가설을 기각하지 않는다고 하는 경우
◎ χ2 Tests(카이제곱검정)
▷ One Sample χ2 test
주어진 데이터가 특정 예상되는 분포와 동일한 분포를 나타내는지 에 대한 가설검정.
Goodness of Fit test라 부르기도 합니다.

χ2통계치 의 계산식

- Scipy 모듈 사용
데이터 1 = [18, 22, 20, 15, 23, 22]
데이터 2 = [5, 23, 26, 19, 24, 23]
주어진 데이터가 특정 예상되는 분포(입력이 없으면 평균으로 계산)를 나타내는지에 대한 가설검정
# 데이터 1
import numpy as np
from scipy.stats import chisquare
s_obs = np.array([[18, 22, 20, 15, 23, 22]]) # Similar
print('--- Similar ---')
chisquare(s_obs, axis=None) # One sample chi-square<출력>
--- Similar ---
Power_divergenceResult(statistic=2.3000000000000003, pvalue=0.8062668698851285)
-> pvalue값이 0.8로 0.05보다 크기때문에 귀무가설을 채택해서 분포가 같다라고 판단
데이터 2
ns_obs = np.array([[5, 23, 26, 19, 24, 23]])
print('--- not Similar ---')
chisquare(ns_obs, axis=None)<출력>
--- not Similar ---
Power_divergenceResult(statistic=14.8, pvalue=0.011251979028327346)
-> pvalue값이 0.01로 0.05보다 작기때문에 귀무가설을 기각한다. 즉, 분포가 다르다
- NumPy 를 사용하여 (Scipy를 사용하지 않고) One Sample χ2 test 방법
import numpy as np
# v1, v2 데이터
v1 = [18,22,20,15,23,22]
v2 = [5,23,26,19,24,23]
def myChisq(value):
obs = np.array(value)
exp1 = sum(obs) / len(obs)
exp = np.array(exp1)
chi1= (obs-exp)
chi2 = (chi1**2) / exp
chi= chi2.sum() # chisquare 값
# p-Value값 구하기
x2 = chi
pvalue = 1 - stats.chi2.cdf(x2, df = len(obs)-1 )
return chi, pvalue
# chisquare값과 pvalue를 출력해야합니다.
myChisq(v1)
myChisq(v2)<출력>
v1 -> 2.3000000000000003, 0.8062668698851285
귀무가설 기각 X
v2 -> 14.8, 0.011251979028327308
귀무가설 기각 O
▷ Two sample χ2 test
- 두개이상의 변수에 대해서 변수끼리의 차이가 있는지 검정
- 데이터 df

# 데이터 계산하기 쉬운 numpy array로 변환
obs = np.array([[54,577,143,782],[2,735,1437,1],[0,142,44,0]])
# scipy 모듈 사용
from scipy.stats import chi2_contingency
chi2_contingency(obs)
# 출력 정리
chi2_stat, p_val, dof, ex = stats.chi2_contingency(obs)
print("=Chi2 Stat=")
print(chi2_stat)
print("\n")
print("=Degrees of Freedom=")
print(dof)
print("\n")
print("=P-Value=")
print(p_val)
print("\n")
print("=Contingency Table=")
print(ex)<출력>

◎ ANOVA 분석 (분산분석)
- 2개 이상 그룹의 평균에 차이가 있는지를 가설 검정할때 사용한다.
다음 4개 그룹에 대해서 평균의 차이가 있는지에 대한 가설 검정을 시행하세요.
A : 38 33 35 92 76 97 88 41 11 9
B : 18 52 62 48 30 40 87 12 97 82
C : 28 90 5 49 66 73 96 80 4 17
D : 8 99 4 12 7 64 18 10 9 20
- 가설
귀무가설 H0 : 4개 그룹에 대해서 평균의 차이가 없다
대립가설 H1 : 4개 그룹에 대해서 평균의 차이가 있다
import scipy.stats as stats
import pandas as pd
import numpy as np
%matplotlib inline
a = [38, 33, 35, 92, 76, 97, 88, 41, 11, 9]
b = [18, 52, 62, 48, 30, 40, 87, 12, 97, 82]
c = [28, 90, 5, 49, 66, 73, 96, 80, 4 ,17]
d = [8, 99, 4, 12, 7, 64, 18, 10, 9, 20]
data = pd.DataFrame(data = {'A' : a, 'B' : b, 'C' : c, 'D' : d})
data
F_statistic, pVal = stats.f_oneway(data['A'], data['B'], data['C'],data['D'])
print('데이터의 일원분산분석 결과 : F={0:.1f}, p={1:.5f}'.format(F_statistic, pVal))<출력>
Altman 910 데이터의 일원분산분석 결과 : F=1.7, p=0.17921
p값이 0.17로 0.05보다 크기 때문에 그룹의 평균값이 통계적으로 유의미하게 차이가 없다.
'DataScience > 통계-선형대수' 카테고리의 다른 글
| 분산(Variance), 표준편차, 공분산(Covariance), 상관계수, Span, 기저(Basis), Rank (0) | 2021.05.25 |
|---|---|
| 벡터와 매트릭스, 스칼라, Determinant, Cramer's rule (0) | 2021.05.24 |
| 통계학 기초 _ 조건부 확률, 베이즈 정리 (0) | 2021.05.22 |
| 통계학 기초_Effective Sampling, 가설 검정, Student T-test(독립T검정)_One Sample t-test, Two Sample T-test (0) | 2021.05.22 |
| 기초수학 코딩 _ 미분이란, 미분 with python, 미분 코딩연습 (4) | 2021.05.20 |