
◎ 교차검증
지금까지는 데이터를 훈련/검증/테스트 세트로 나누어 학습을 진행해 왔습니다.(이 방법은 hold-out 교차검증 이라고 합니다.) 이 방법은 어떤 문제점을 가지고 있을까요?
- 학습에 사용가능한 데이터가 충분하다면 문제가 없겠지만, 훈련세트의 크기가 모델학습에 충분하지 않을 경우 문제가 될 수 있습니다.
- 검증세트 크기가 충분히 크지 않다면 예측 성능에 대한 추정이 부정확할 것입니다.
이것 외에 다른 문제점도 있습니다. 여러분은 앞으로 수많은 기계학습 알고리즘을 사용할 것인데 모든 문제에 적용가능한 최고의 학습 모델은 없다는 것을 알고 계시지요?
- 우리 문제를 풀기위해 어떤 학습 모델을 사용해야 할 것인지?
- 어떤 하이퍼파라미터를 사용할 것인지?
이러한 문제가 모델선택(Model selection) 문제입니다.
이렇게 데이터의 크기에 대한 문제, 모델선택에 대한 문제를 해결하기 위해 사용하는 방법 중 한 가지가 교차검증입니다.
참고:교차검증은 시계열(time series) 데이터에는 적합하지 않습니다

★ 하이퍼 파라미터 튜닝
머신러닝 모델을 만들때 중요한 이슈는 최적화(optimization)와 일반화(generalization)이다.
- 최적화는 훈련 데이터로 더 좋은 성능을 얻기 위해 모델을 조정하는 과정이며,
- 일반화는 학습된 모델이 처음 본 데이터에서 얼마나 좋은 성능을 내는지를 이야기 한다.
모델의 복잡도를 높이는 과정에서 훈련/검증 세트의 손실이 함께 감소하는 시점은 과소적합(underfitting) 되었다고 한다.
이 때는 모델이 더 학습 될 여지가 있다. 하지만 어느 시점부터 훈련데이터의 손실은 계속 감소하는데 검증데이터의 손실은 증가하는 때가 있다. 이때 우리는 과적합(overfitting) 되었다고 한다.
이상적인 모델은 과소적합과 과적합 사이에 존재한다.
사실 하나의 파라미터만 가지고 검증곡선을 그리는 것이 현실적으로 아주 유용하지는 않습니다. 현실에서는 더 많은 파라미터의 변화에 대한 결과를 보는 것이 중요하지요.
한 번 결정트리에서 과적합을 막아줄 때 제한하는 max_depth를 변화시키며 검증곡선을 그려봅시다.

▷ 모델 1 : 단순 교차검증만 수행하는 K-fold CV
교차검증을 하기 위해서는 데이터를 k개로 등분하여야 하는데 이를 k-fold cross-validation(CV) 라고 합니다.
예를들어, 데이터를 3등분으로 나누고 검증(1/3)과 훈련세트(2/3)를 총 세번 바꾸어가며 검증하는 것은 3-fold CV 입니다. 개인적으로 최근 개발 된 모델은 하이퍼 파라미터를 찾아주고 교차검증까지 같이 해주기 때문에 잘 사용하지 않는 것같음.
- Ridge모델
# Ridge모델의 K-fold 교차검증
from category_encoders import OneHotEncoder
from sklearn.feature_selection import f_regression, SelectKBest
from sklearn.impute import SimpleImputer
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
np.seterr(divide='ignore', invalid='ignore')
target = 'SalePrice'
features = train.columns.drop([target])
X_train = train[features]
y_train = train[target]
X_test = test[features]
y_test = test[target]
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True),
SimpleImputer(strategy='mean'),
StandardScaler(),
SelectKBest(f_regression, k=20),
Ridge(alpha=1.0)
)
# 3-fold 교차검증을 수행합니다.
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv=k,
scoring='neg_mean_absolute_error')
print(f'MAE ({k} folds):', -scores)MAE (3 folds): [19912.3716215 23214.74205495 18656.29713167]
평균 : 20594.470269371817
- 랜덤포레스트
from category_encoders import TargetEncoder
from sklearn.ensemble import RandomForestRegressor
pipe = make_pipeline(
# TargetEncoder: 범주형 변수 인코더로, 타겟값을 특성의 범주별로 평균내어 그 값으로 인코딩
TargetEncoder(min_samples_leaf=1, smoothing=1),
SimpleImputer(strategy='median'),
RandomForestRegressor(max_depth = 10, n_jobs=-1, random_state=2)
)
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv=k,
scoring='neg_mean_absolute_error')
print(f'MAE for {k} folds:', -scores)MAE for 3 folds: [16289.34502313 19492.01218055 15273.23000751]
평균 : 17018.19573706592
▷ 모델 2 : 파라미터 튜닝과 교차검증을 수행하는 Randomized Search CV
현실적으로 하이퍼파라미터를 수작업으로 정해주는 것은 어렵다. 최적의 하이퍼파라미터 조합을 찾아주는 도구를 사용해야 한다. 사이킷런에 하이퍼파라미터 튜닝을 도와주는 좋은 툴이 두 가지 있다.
- GridSearchCV: 검증하고 싶은 하이퍼파라미터들의 수치를 정해주고 그 조합을 모두 검증
- RandomizedSearchCV: 검증하려는 하이퍼파라미터들의 값 범위를 지정해주면 무작위로 값을 지정해 그 조합을 모두 검증
- Ridge 회귀모델
from sklearn.model_selection import RandomizedSearchCV
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True)
, SimpleImputer()
, StandardScaler()
, SelectKBest(f_regression)
, Ridge()
)
# 튜닝할 하이퍼파라미터의 범위를 지정해 주는 부분
dists = {
'simpleimputer__strategy': ['mean', 'median'],
'selectkbest__k': range(1, len(X_train.columns)+1),
'ridge__alpha': [0.1, 1, 10],
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=50,
cv=3,
scoring='neg_mean_absolute_error',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);
print('최적 하이퍼파라미터: ', clf.best_params_)
print('MAE: ', -clf.best_score_)최적 하이퍼파라미터: {'simpleimputer__strategy': 'median', 'selectkbest__k': 55, 'ridge__alpha': 10} MAE: 18414.633797820472
- 랜덤 포레스트
from scipy.stats import randint, uniform
pipe = make_pipeline(
TargetEncoder(),
SimpleImputer(),
RandomForestRegressor(random_state=2)
)
dists = {
'targetencoder__smoothing': [2.,20.,50.,60.,100.,500.,1000.], # int로 넣으면 error(bug)
'targetencoder__min_samples_leaf': randint(1, 10),
'simpleimputer__strategy': ['mean', 'median'],
'randomforestregressor__n_estimators': randint(50, 500),
'randomforestregressor__max_depth': [5, 10, 15, 20, None],
'randomforestregressor__max_features': uniform(0, 1) # max_features
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=50,
cv=3,
scoring='neg_mean_absolute_error',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);
print('최적 하이퍼파라미터: ', clf.best_params_)
print('MAE: ', -clf.best_score_)최적 하이퍼파라미터: {'max_depth': 20, 'max_features': 0.22612308958451122, 'n_estimators': 498, 'simpleimputer__strategy': 'mean', 'targetencoder__min_samples_leaf': 8, 'targetencoder__smoothing': 1000.0}
MAE: 15741.360087309344
▷ 모델 3 : 파라미터 튜닝과 교차검증을 수행하는 GridSearchCV
대략적인 하이퍼 파라미터의 범위를 randomizedserchCV로 알아본 뒤 더 높은 성능을 나타내는 GridSearchCV를 범위를 줄여서 사용(범위를 줄이는 이유는 성능은 높지만 모델링 시간이 가장 오래걸림)
- 랜덤포레스트(캐글컴피티션 참여데이터)
import pandas as pd
from sklearn.model_selection import train_test_split
url_train = "https://raw.githubusercontent.com/ZeusKwon/data-drive/main/prediction-of-h1n1-vaccination/train.csv"
url_train_labels="https://raw.githubusercontent.com/ZeusKwon/data-drive/main/prediction-of-h1n1-vaccination/train_labels.csv"
url_test = "https://raw.githubusercontent.com/ZeusKwon/data-drive/main/prediction-of-h1n1-vaccination/test.csv"
url_submission = "https://raw.githubusercontent.com/ZeusKwon/data-drive/main/prediction-of-h1n1-vaccination/submission.csv"
target = 'vacc_h1n1_f'
df = pd.merge(pd.read_csv(url_train),
pd.read_csv(url_train_labels)[target],
left_index=True, right_index=True)
test = pd.read_csv(url_test)
submission = pd.read_csv(url_submission)
train, val = train_test_split(df, train_size=0.80, test_size=0.20, stratify=df[target], random_state=2)
train.shape, val.shape, test.shape((33723, 39), (8431, 39), (28104, 38))
# Target encoder 사용 (mean-encoding)
from sklearn.pipeline import make_pipeline, Pipeline
from category_encoders import TargetEncoder
def engineer_base(df):
df = df.drop(['household_children','n_adult_r'], axis = 1)
behaviorals = [col for col in df.columns if 'behavioral' in col]
for i in df["employment_status"]:
if i == "Not in Labor Force":
fixed_data.append("Unemployed")
else:
fixed_data.append(i)
df["employment_status"] = fixed_data
return df
train_base = engineer_base(train)
val_base = engineer_base(val)
test_base = engineer_base(test)
features = train_base.drop(columns=[target]).columns
x_train_base = train_base[features]
y_train_base = train_base[target]
x_val_base = val_base[features]
y_val_base = val_base[target]
x_test_base = test_base[features]
from category_encoders import TargetEncoder
TE_encoder = TargetEncoder()
train_te = TE_encoder.fit_transform(x_train_base, y_train_base)
val_te = TE_encoder.transform(x_val_base)
pipe = Pipeline([('imp',SimpleImputer(strategy = 'mean')),
('scaler',MinMaxScaler()),
('rf',RandomForestClassifier(criterion = 'gini',
class_weight = 'balanced',
max_features = 0.25,
n_jobs=2,
min_samples_leaf = 10,
random_state=10))])
stratifiedkfold = StratifiedKFold(n_splits=4, shuffle = True, random_state = 42)
param_grid = {'rf__n_estimators': [1000,1100,1200],
'rf__max_depth' : [15,20, 25]}
gridsearch_te = GridSearchCV(pipe, param_grid, cv=stratifiedkfold, scoring ='f1', n_jobs=2, verbose=2)
gridsearch_te.fit(train_te, y_train_base)
print('Best Parameter :', gridsearch_te.best_params_)
print('Best Score : ', gridsearch_te.best_score_)
model_te = gridsearch_te.best_estimator_
train_pred_te = model_te.predict(train_te)
val_pred_te = model_te.predict(val_te)
print('\n훈련 정확도: ', model_te.score(train_te, y_train_base))
print('훈련 f1_score:', f1_score(y_train_base, train_pred_te))
print('\n검증 정확도: ', model_te.score(val_te, y_val_base))
print('검증 f1_score:', f1_score(y_val_base, val_pred_te))Best Parameter : {'rf__max_depth': 25, 'rf__n_estimators': 1200}
Best Score : 0.6181923784776887
훈련 정확도: 0.8396643240518341
훈련 f1_score: 0.7058375496436539
검증 정확도: 0.8044122879848179
검증 f1_score: 0.6387732749178532
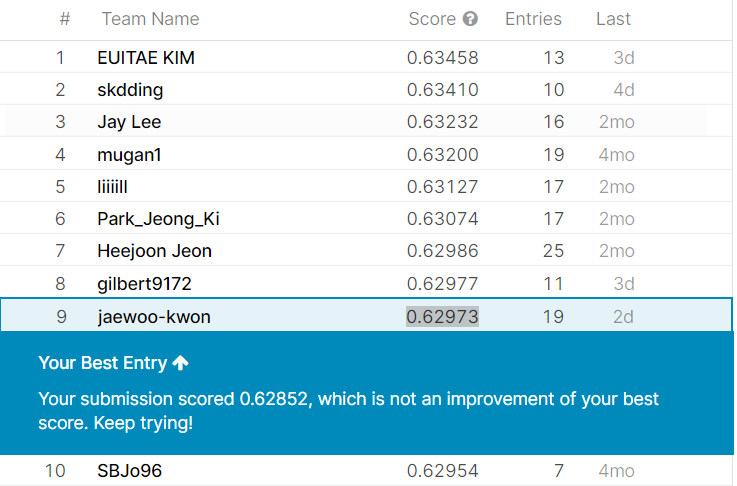
- > 캐글 최종 스코어 : 0.62973 (총합 9위)
▷ 선형회귀, 랜덤포레스트 모델들의 튜닝 추천 하이퍼파라미터
- Random Forest
- class_weight (불균형(imbalanced) 클래스인 경우)
- max_depth (너무 깊어지면 과적합)
- n_estimators (적을경우 과소적합, 높을경우 긴 학습시간)
- min_samples_leaf (과적합일경우 높임)
- max_features (줄일 수록 다양한 트리생성)
- Logistic Regression
- C (Inverse of regularization strength)
- class_weight (불균형 클래스인 경우)
- penalty
- Ridge / Lasso Regression
- alpha
'DataScience > 인공지능' 카테고리의 다른 글
| 가상환경 구성 및 주피터(jupyter notebook) 연결 (0) | 2023.01.27 |
|---|---|
| DL.4 _ 신경망 용어정리, Keras Hyperparameters (0) | 2021.08.17 |
| DL.3 _ keras 하이퍼파라미터, 활동함수(Activation function) (0) | 2021.08.11 |
| DL.1.1 _ 인공신경망이란, 퍼셉트론 알고리즘 (0) | 2021.08.11 |
| ML _ 모델 성능 평가지표 (0) | 2021.06.21 |