
Word2Vec
2013년에 고안된 Word2Vec 말 그대로 단어를 벡터로(Word to Vector) 나타내는 방법으로 가장 널리 사용되는 임베딩 방법 중 하나이다
Word2Vec은 특정 단어 양 옆에 있는 두 단어(window size = 2)의 관계를 활용하기 때문에 분포 가설을 잘 반영하고 있다. Word2Vec에는 CBoW와 Skip-gram의 2가지 방법이 있습니다.
- CBoW 와 Skip-gram
- 주변 단어에 대한 정보를 기반으로 중심 단어의 정보를 예측하는 모델인지 => CBoW(Continuous Bag-of-Words)
- 중심 단어의 정보를 기반으로 주변 단어의 정보를 예측하는 모델인지 => Skip-gram

FastText
fastText 는 Word2Vec 방식에 철자(Character) 기반의 임베딩 방식을 더해준 새로운 임베딩 방식이다.
fastText 가 고안된 이유는 OOV(Out of Vocabulary)문제 때문이다.
1) OOV(Out of Vocabulary) 문제
Word2Vec 은 말뭉치에 등장하지 않은 단어에 대해서는 임베딩 벡터를 만들지 못한다는 단점이 있다. 이렇게 기존 말뭉치에 등장하지 않는 단어가 등장하는 문제를 OOV(Out of Vocabulary) 문제라고 한다.
2) 철자 단위 임베딩(Character level Embedding)
fastText 는 철자(Character) 수준의 임베딩을 보조 정보로 사용함으로써 OOV 문제를 해결해냈다.
fastText는 단어의 앞뒤로 "<",">"를 붙여준 뒤 해당 단어를 3-6개 Character-level로 잘라서 임배딩을 적용하는 방법이다.
예시)

이와 같은 방식을 3개 부터 6개까지 진행한 뒤 임베딩 벡터를 생성하고 원래 eating 의 임베딩 벡터와 함께 사용한다.

eating 이라는 단어가 말뭉치 내에 있다면 skip-gram으로부터 학습한 임베딩 벡터에 위에서 얻은 18개 Character-level n-gram 들의 벡터를 더해준다.
반대로, eating 이라는 단어가 말뭉치에 없다면 18개 Character-level n-gram 들의 벡터만으로 구성한다.
언어 모델 (Language Model)
언어 모델이란 문장과 같은 단어 시퀀스에서 각 단어의 확률을 계산하는 모델이고 Word2Vec 역시 여러 가지 언어 모델 중 하나이다.
1) 통계적 언어 모델 (Statistical Language Model, SLM)
통계적 언어 모델에서는 단어의 등장 횟수를 바탕으로 조건부 확률을 계산한다.
통계적 언어 모델의 한계점
통계적 언어 모델은 횟수 기반으로 확률을 계산하기 때문에 희소성(Sparsity) 문제를 가지고 있다. 예를 들어, 학습시킬 말뭉치에 "1 times", "2 times", ... 라는 표현은 등장하지만 "7 times" 라는 표현은 없다고 해보겠다.
그렇다면 이 말뭉치를 학습한 통계적 언어 모델은 아래와 같은 문장을 절대 만들어 낼 수 없게 된다.
2) 신경망 언어 모델 (Neural Langauge Model)
신경망 언어 모델에서는 횟수 기반 대신 Word2Vec이나 fastText 등의 출력값인 임베딩 벡터를 사용한다.
그렇기 때문에 말뭉치에 등장하지 않더라도 의미적, 문법적으로 유사한 단어라면 선택될 수 있다.
순환 신경망 (RNN, Recurrent Neural Network)
출력벡터가 다시 입력되는 특성을 가진 신경망을 순환 신경망이라고 부른다.
- 연속형 데이터 (Sequential Data)
- 자연어 데이터
- 시계열 데이터(ex 주식)
- 비연속성 데이터(Non-sequential Data)
- 이미지 데이터
- 테이블 데이터(ex pandas)
1) RNN
RNN은 연속형 데이터를 잘 처리하기 위해 고안된 신경망이다.
- RNN의 구조

출력벡터가 다시 입력벡터가 되는것을 볼 수 있다.
- 다양한 RNN의 형태

- one-to-many : 1개의 벡터를 받아 Sequential한 벡터를 반환합니다. 이미지를 입력받아 이를 설명하는 문장을 만들어내는 이미지 캡셔닝(Image captioning)에 사용됩니다.
- many-to-one : Sequential 벡터를 받아 1개의 벡터를 반환합니다. 문장이 긍정인지 부정인지를 판단하는 감성 분석(Sentiment analysis)에 사용됩니다.
- many-to-many(1) : Sequential 벡터를 모두 입력받은 뒤 Sequential 벡터를 출력합니다. 시퀀스-투-시퀀스(Sequence-to-Sequence, Seq2Seq) 구조라고도 부릅니다. 번역할 문장을 입력받아 번역된 문장을 내놓는 기계 번역(Machine translation)에 사용됩니다.
- many-to-many(2) : Sequential 벡터를 입력받는 즉시 Sequential 벡터를 출력합니다. 비디오를 프레임별로 분류(Video classification per frame)하는 곳에 사용됩니다.
- RNN의 장.단점
- 장점
- 모델이 간단하고 어떤 길이의 sequential 데이터라도 처리 할 수 있다는 장점을 가지고 있다.
- 단점
- 병렬화 불가능
- 기울기 폭발(Exploding Gradient), 기울기 소실(Vanishing Gradient)
- LSTM & GRU
RNN의 단점을 보완하기 위해 개발된 알고리즘
LSTM (Long Term Short Memory, 장단기기억망)
LSTM이 등장한 배경은 기울기 소실(Vanishing Gradient) 문제를 해결하기 위함이다.
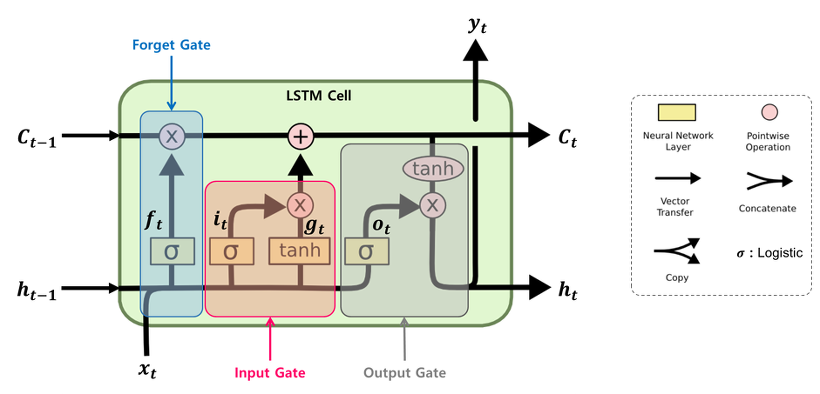
- RNN에 기울기 정보 크기를 조절하기 위한 Gate가 추가된 모델
- hidden-state 말고도 활성화 함수를 직접 거치지 않는 상태인 cell-state 가 추가되었고 역전파 과정에서 활성화 함수를 거치지 않기 때문에 정보 손실이 없다.
- 시계열 알고리즘에서는 대부분 LSTM을 사용한다.
GRU (Gated Recurrent Unit)
LSTM 알고리즘은 너무 복잡하지만 간소한 버전인 GRU도 있다.

- LSTM에서 있었던 cell-state가 없다.
- LSTM에서는 출력, 입력, 삭제라는 3개의 게이트가 있었지만 GRU에서는 업데이트, 리셋 게이트만 존재한다.
- 성능은 GRU가 빠르다고 알려져 있지만 둘 다 성능에는 큰 차이가 없다.
- 데이터 양이 적을 때는 GRU가 더 낫고, 데이터의 양이 많으면 LSTM이 더 낫다고 알려져 있다.
- RNN 구조에 Attention 적용
기존 RNN 기반(LSTM, GRU) 번역 모델의 단점
RNN이 가진 가장 큰 단점 중 하나는 기울기 소실로부터 나타나는 장기 의존성(Long-term dependency) 문제이다.
장기 의존성 문제란 문장이 길어질 경우 앞 단어의 정보를 잃어버리게 되는 현상이다.
장기 의존성 문제를 해결하기 위해 나온 것이 셀 구조를 개선한 LSTM과 GRU이다.
Attention의 등장
Attention은 RNN이 가진 단점을 보완하기 위해 등장했다.고 정 길이의 hidden-state 벡터에 모든 단어의 의미를 담아야 한다는 점인데 아무리 LSTM, GRU가 장기 의존성 문제를 개선하였더라도 문장이 매우 길어지면(30-50 단어) 모든 단어 정보를 고정 길이의 hidden-state 벡터에 담기 어렵다.
이런 문제를 해결하기 위해서 고안된 방법이 바로 Attention(어텐션) 이다.
Attention은 각 인코더의 Time-step 마다 생성되는 hidden-state 벡터를 간직한다.
입력 단어가 N개라면 N개의 hidden-state 벡터를 모두 간직하게 된다.
모든 단어가 입력되면 생성된 hidden-state 벡터를 모두 디코더에 넘겨준다.
'DataScience > NLP' 카테고리의 다른 글
| DL.5 _ 자연어처리(NLP) (0) | 2021.08.17 |
|---|